Key Concepts of a Schema Registry



Danica Fine
Senior Developer Advocate (Presenter)
Implied Contract Between Kafka Applications
If you’re a programmer you’ll be familiar with APIs, whether it’s a RESTful API or an object interface between your code and some other module or library. APIs provide a contract between two programs or modules. A contract usually encapsulates state and behavior. In event-driven programming there is no parallel for behavior—it’s a pure data discipline—but schemas and the schema registry provide the explicit contract that a program producing events provides to other programs that are consuming them. Implementing schemas over your data is essential for any enduring event streaming system, particularly ones that share data between different microservices or teams—programs that will vary independently of one another and hence value having a well-defined contract for the data they share.
In this module you will learn about the key concept of using schemas as contracts, stored in a schema registry. You will learn about Kafka’s loosely coupled design and how it solves one problem but opens the door for client applications to possibly get out of sync with each other as you make changes to the design and structure of your model objects. We’ll also describe how a schema registry provides what you need to keep client applications in sync with the data changes in your organization or business.
So let’s dive in and learn about the schema registry now.
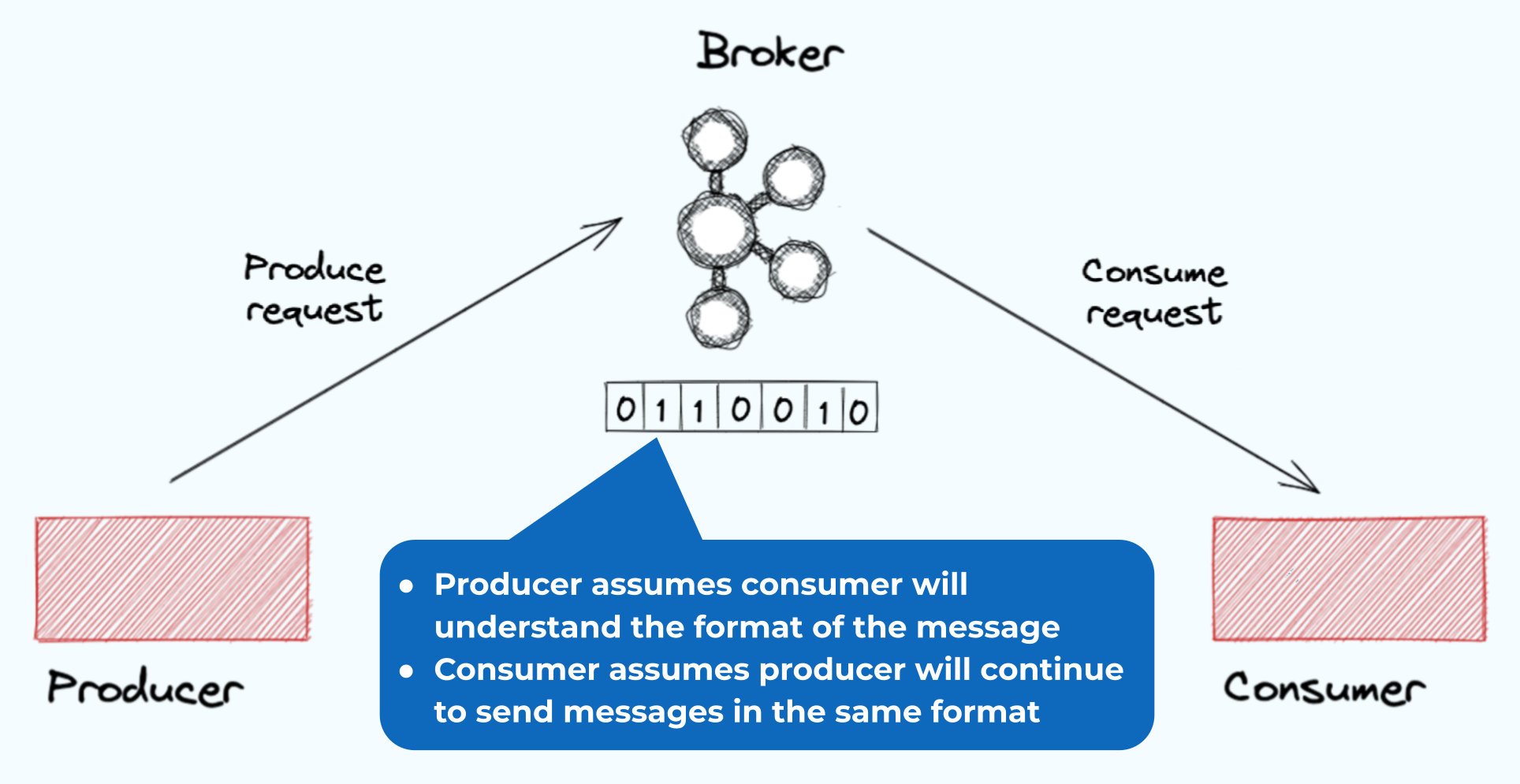
Applications that leverage Kafka fall into two categories: they are either producers or consumers (or both in some cases).
- Producers generate messages or events which are then published to Kafka. These take the form of key-value records which the producers serialize into byte arrays and send to Kafka brokers. The brokers store these serialized records into designated topics.
- Consumers subscribe to one or more topics, request the stored events, and process them. Consumers must be able to deserialize the bytes, returning them to their original record format.
This creates an implicit contract between the two applications. There is an assumption from the producer that the consumer will understand the format of the message. Meanwhile, the consumer also assumes that the producer will continue to send the messages in the same format.
But what if that isn’t the case?
Change Always Happens
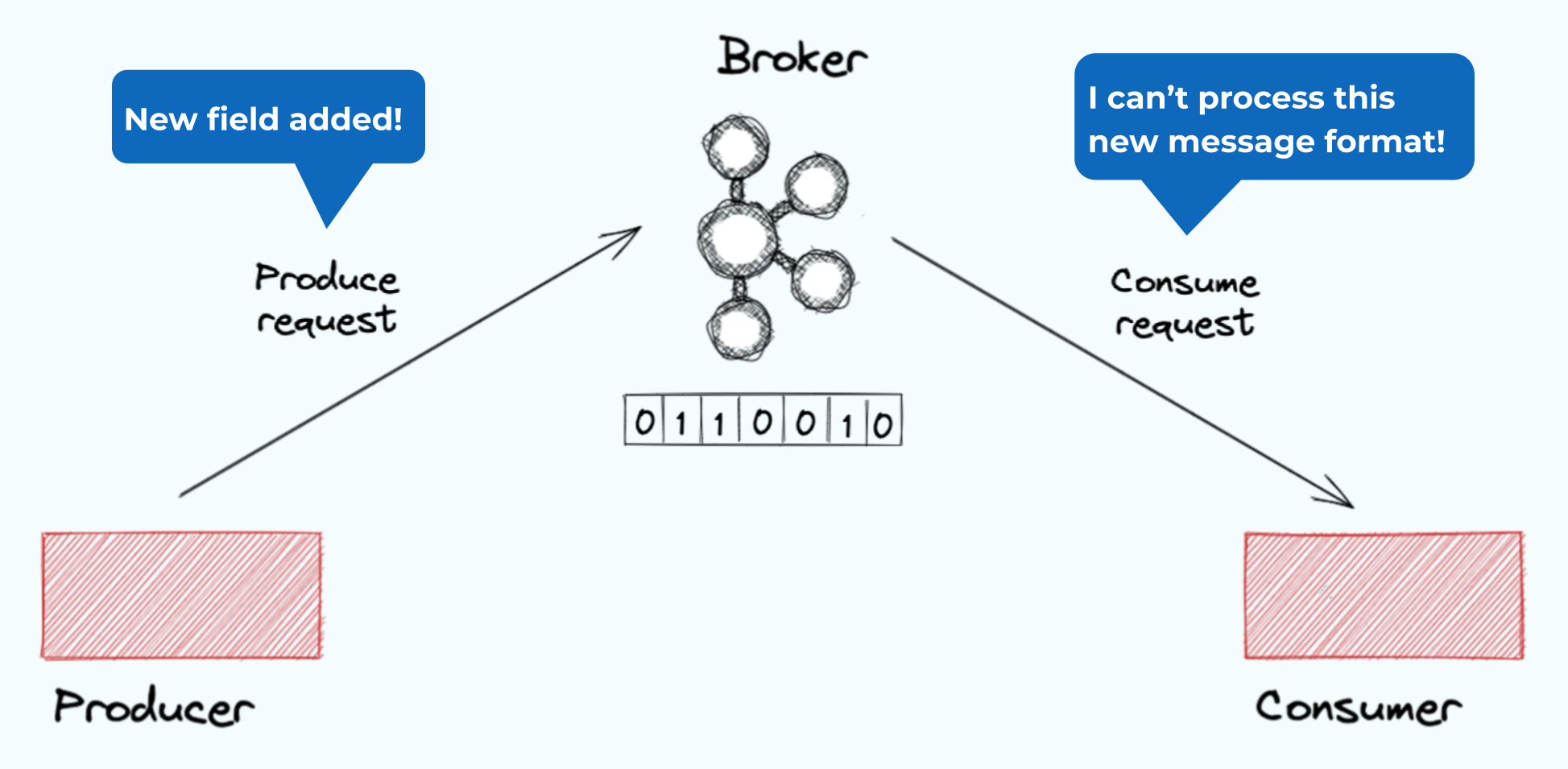
Applications are rarely static. Over time, they evolve as new business requirements develop. These new requirements may result in changes to the format of the message. This could be something simple such as adding or removing a field. Or it could be more complex involving structural changes to the message. It may even mean a different serialization format, such as converting Avro to Protobuf.
When this happens, if both the producer and consumer are not updated at the same time, then the contract is broken. You could end up in a situation where the producer uses one format, but the consumer expects something different. The result is that messages could get stuck in the topic and the consumer may be unable to proceed.
The Schema Is the Contract
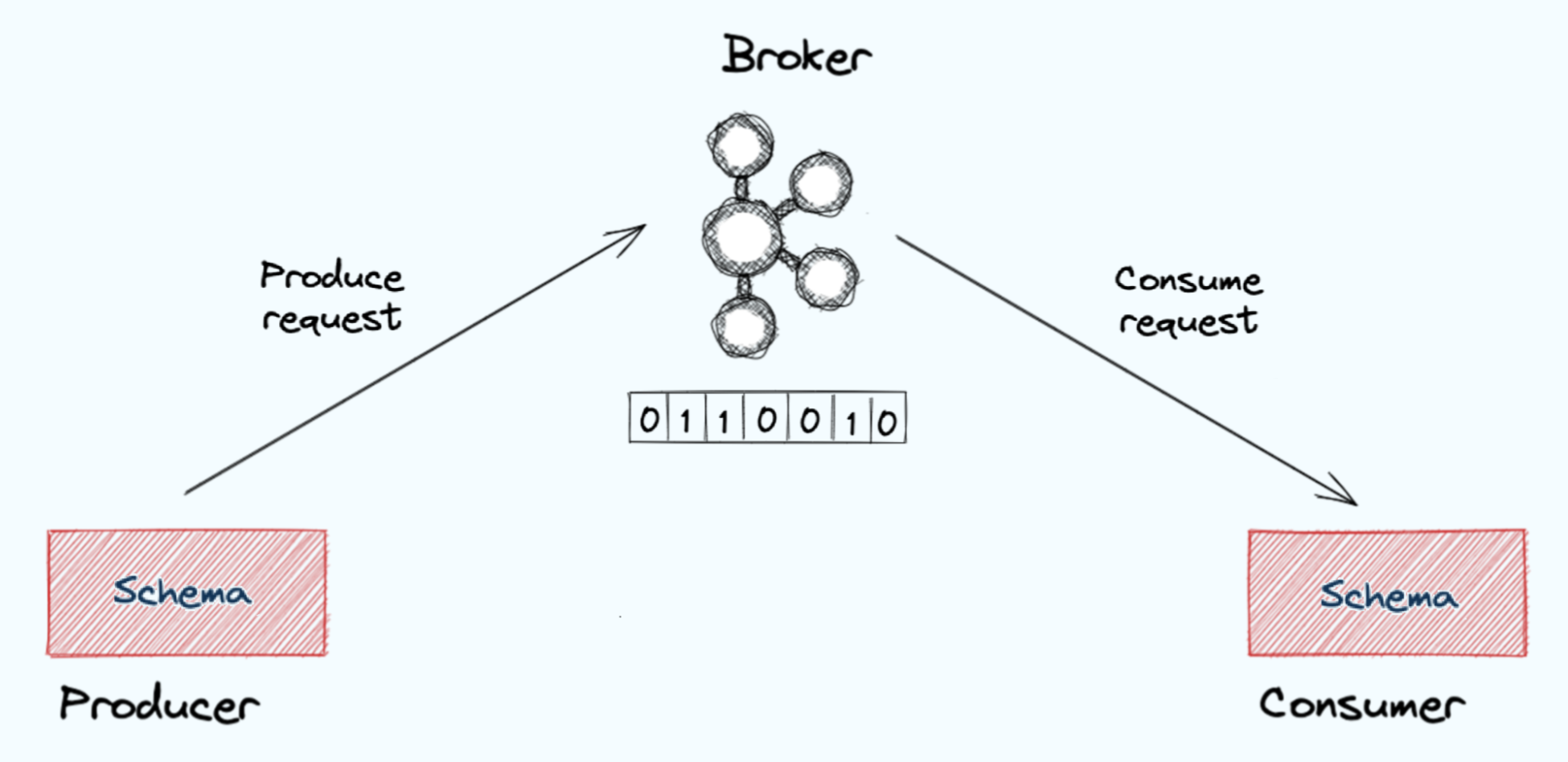
In the real world, when you want to establish a concrete set of rules for how two parties should behave, you sometimes do that in the form of a legal contract. If either of the two parties violate that contract, there are consequences.
In software, you want to provide a similar contract. If either your producer or consumer fails to meet the rules established by the contract, there needs to be a consequence. This contract is codified in something called a schema.
Schemas Establish the Format of the Message
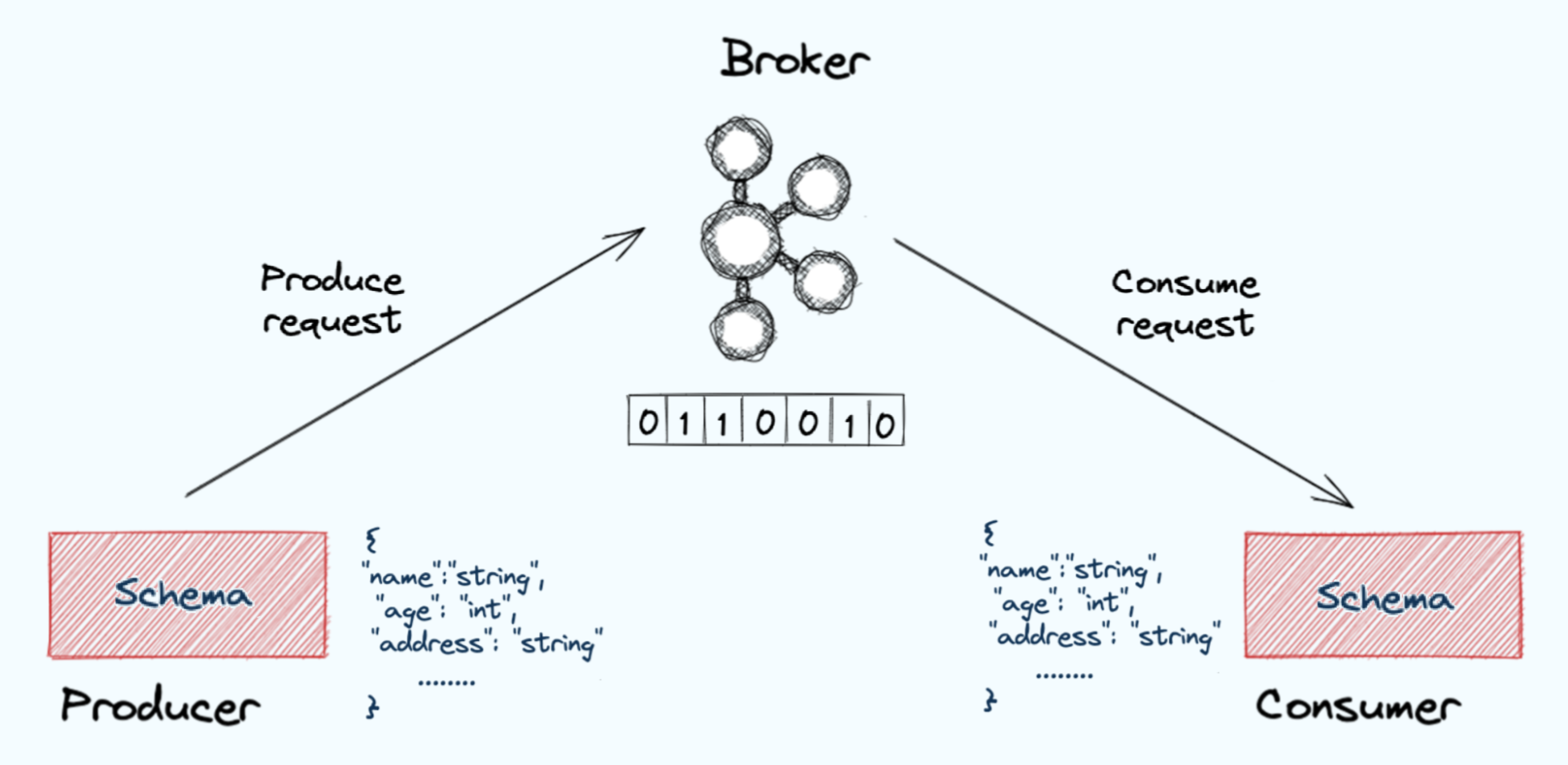
A schema is a set of rules that establishes the format of the messages being sent. It outlines the structure of the message, the names of any fields, what data types they contain, and any other important details. This schema is a contract between the two applications. Both the producer and consumer are expected to support the schema. If the schema needs to change for some reason, then you need to have processes in place to handle that change. For example, you may need to support the old schema for a period of time while both applications are being updated.
Schema Registry Is the Contract Arbitrator
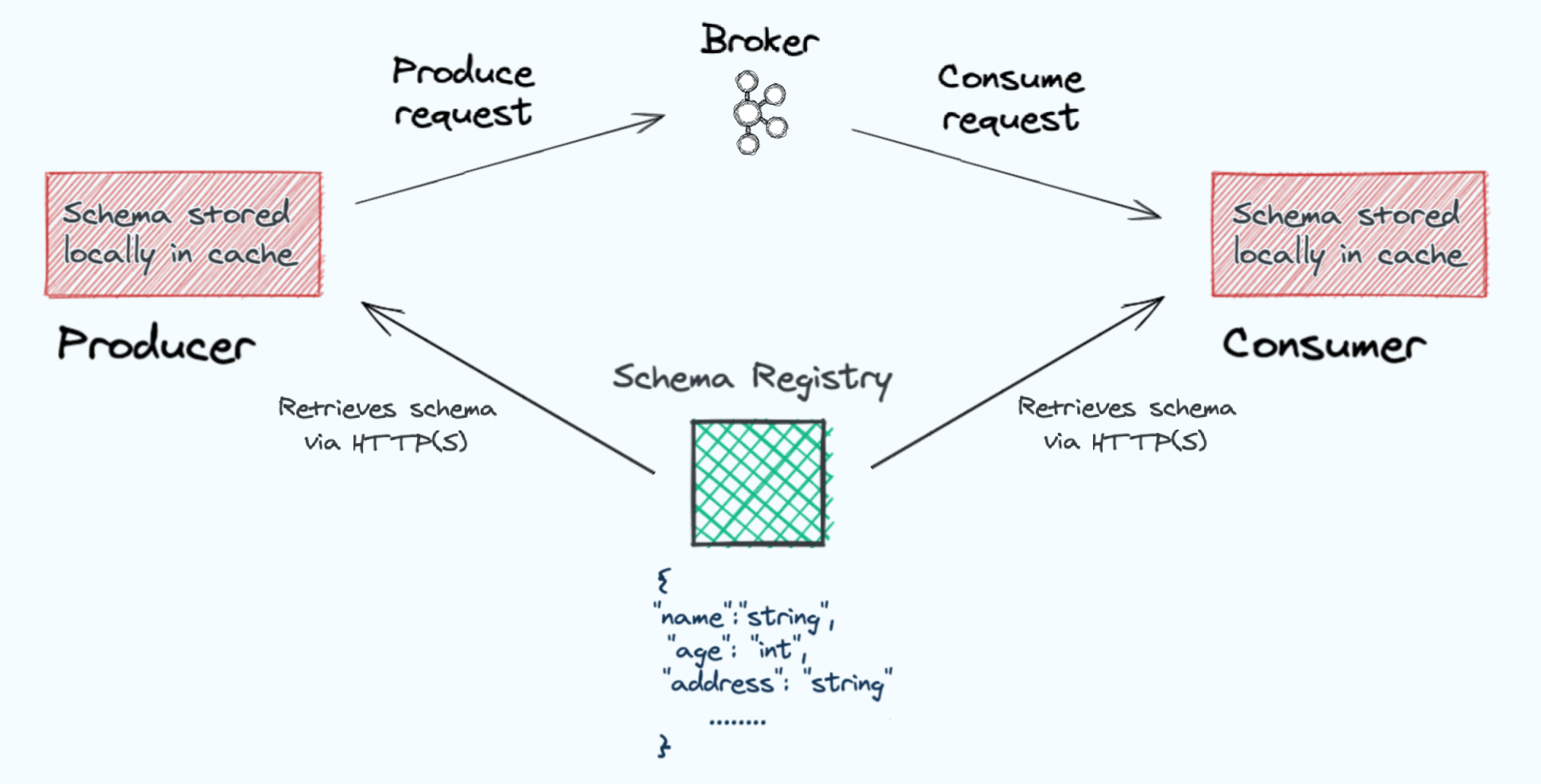
Returning to the real world, when a contract is written, someone is assigned to arbitrate that contract and ensure it is followed. This is generally handled by lawyers. In software the arbiter of the contract is something known as a schema registry. The schema registry is a service that records the various schemas and their different versions as they evolve. Producer and consumer clients retrieve schemas from the schema registry via HTTPS, store them locally in cache, and use them to serialize and deserialize messages sent to and received from Kafka. This schema retrieval occurs only once for a given schema and from that point on the cached copy is relied upon.
Confluent Schema Registry
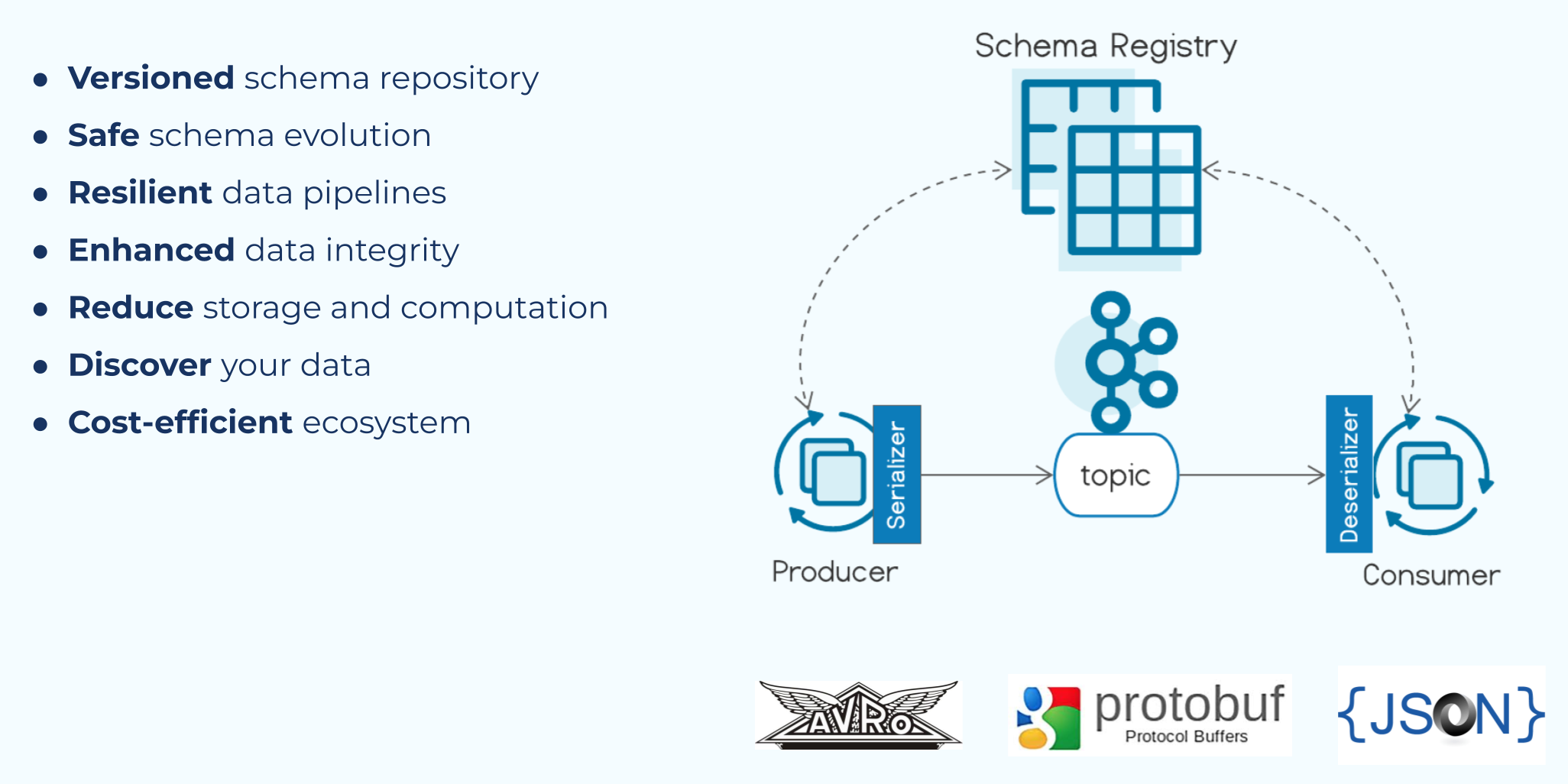
Confluent provides a schema registry that is integrated directly into your Kafka applications. It supports Avro, Protobuf, and JSON schema formats. While much of the information in this course is applicable to any schema registry, the focus is on Confluent Schema Registry. As such, from this point forward the course will refer to it simply as the schema registry with the understanding that it is the Confluent Schema Registry being discussed.
Start Kafka in Minutes with Confluent Cloud
This course introduces you to Confluent Schema Registry through hands-on exercises that will have you produce data to and consume data from Confluent Cloud. If you haven’t already signed up for Confluent Cloud, sign up now so when your first exercise asks you to log in, you are ready to do so.
- Browse to the sign-up page: https://www.confluent.io/confluent-cloud/tryfree/ and fill in your contact information and a password. Then click the START FREE button and wait for a verification email.
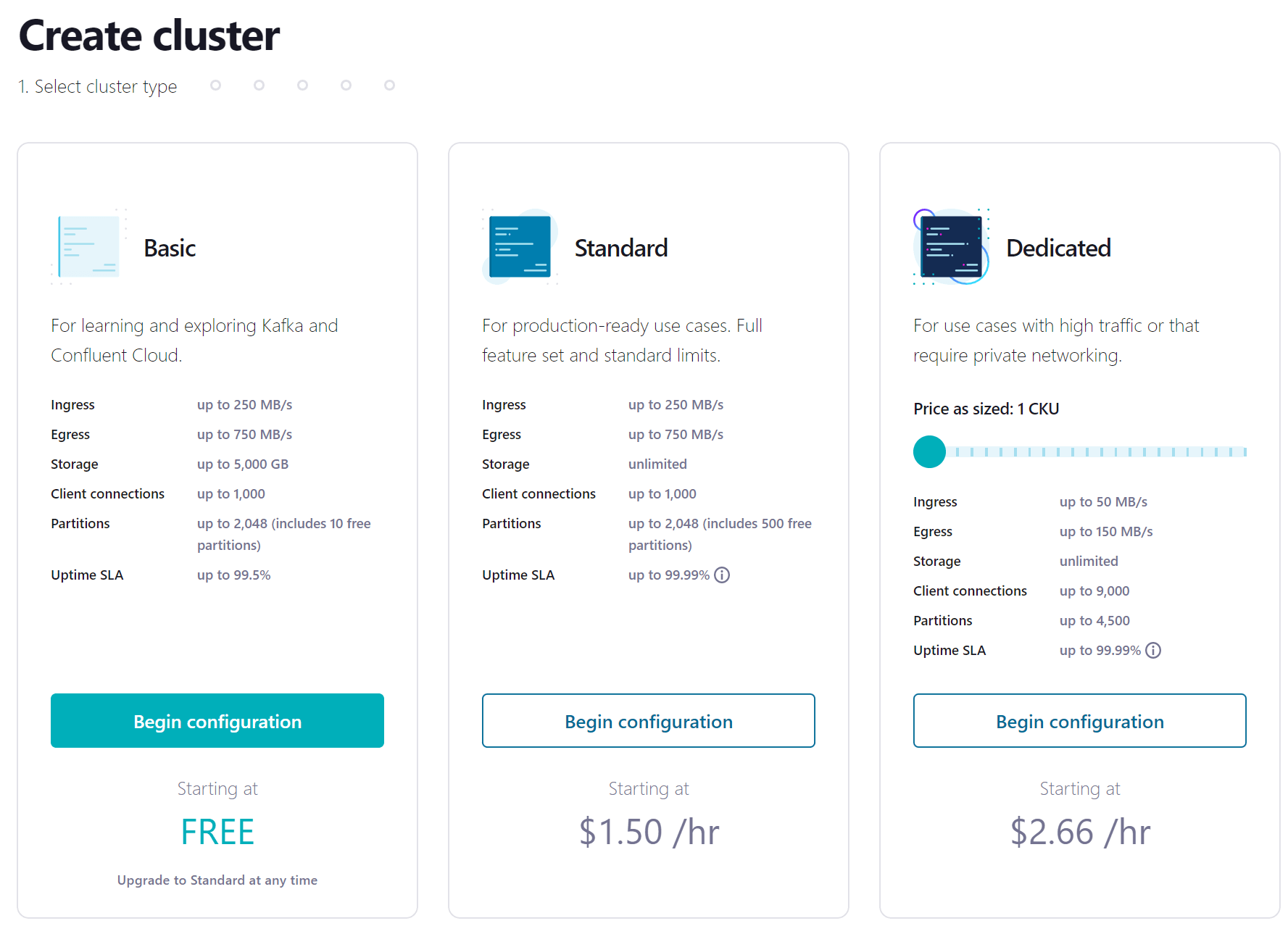
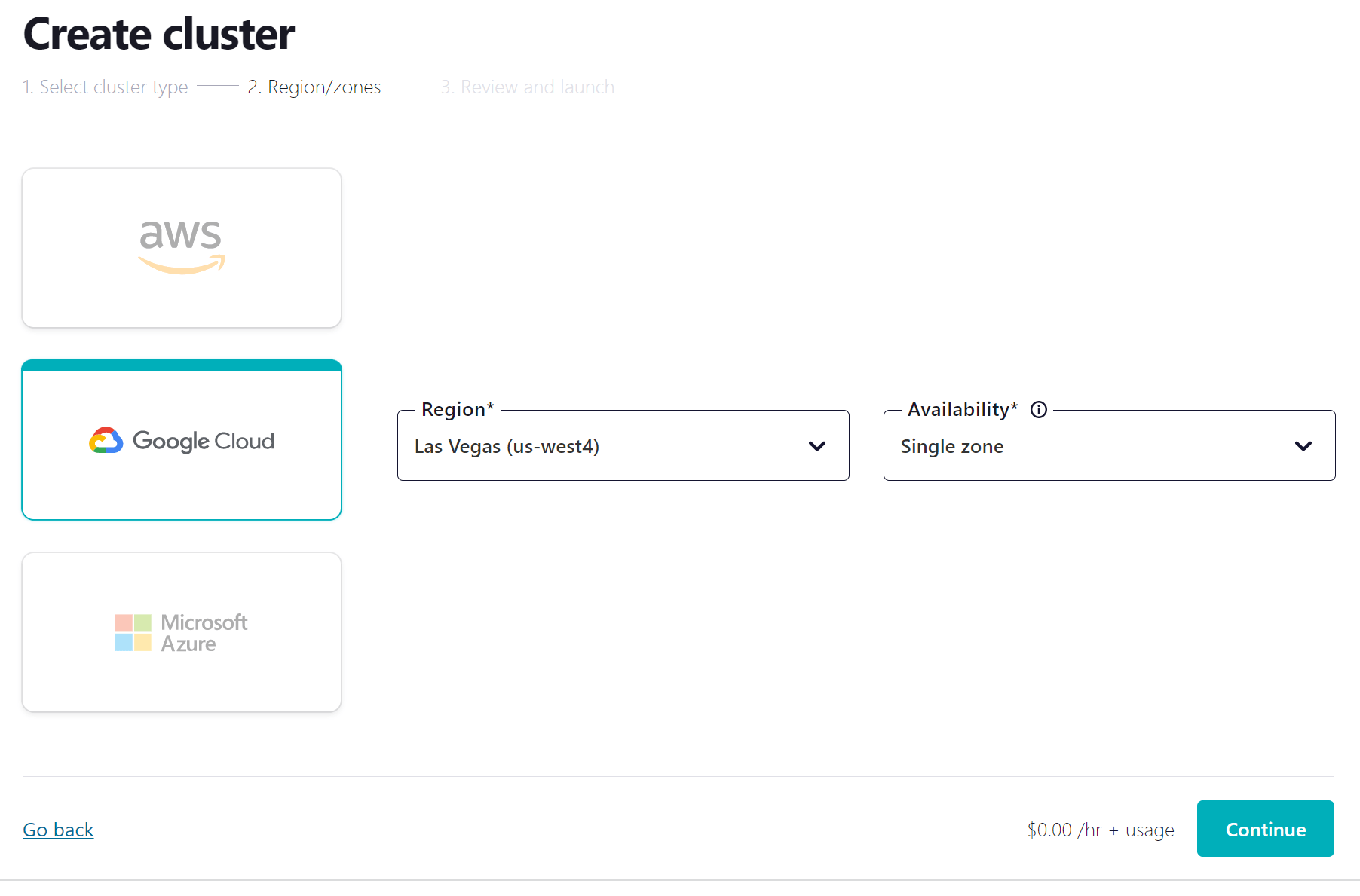
- Click the link in the confirmation email and then follow the prompts (or skip) until you get to the Create cluster page. Here you can see the different types of clusters that are available, along with their costs. For this course, the Basic cluster will be sufficient and will maximize your free usage credits. After selecting Basic, click the Begin configuration button.
- Choose your preferred cloud provider and region, and click Continue.
-
Review your selections and give your cluster a name, then click Launch cluster. This might take a few minutes.
-
While you’re waiting for your cluster to be provisioned, be sure to add the promo code SCHEMA101 to get an additional $25 of free usage (details). From the menu in the top right corner, choose Administration | Billing & Payments, then click on the Payment details tab. From there click on the +Promo code link, and enter the code.
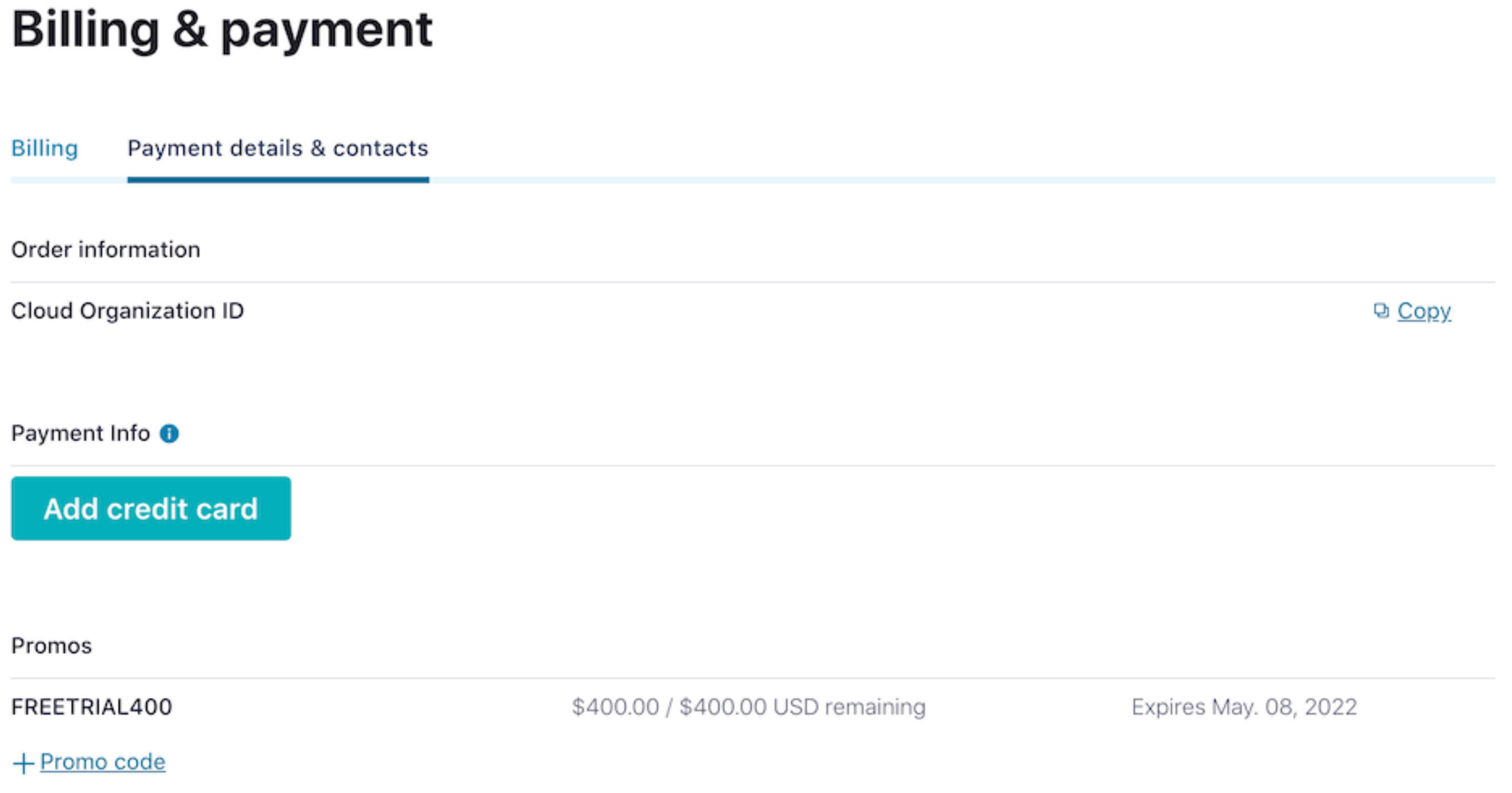
You’re now ready to complete the upcoming exercises as well as take advantage of all that Confluent Cloud has to offer!
- Previous
- Next
Use the promo code SCHEMA101 to get $25 of free Confluent Cloud usage
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.
Key Concepts of a Schema Registry
Hi, I'm Danica Fine, here to introduce you to key concepts of the Schema Registry. If you're a programmer, you'll be familiar with APIs. Whether it's a restful API, or an object interface between your code and some other module or library, APIs provide a contract between two programs or modules, a contract that usually encapsulates state and behavior. Now, in event-driven programming, you may have noticed that there isn't really a parallel behavior. It's a pure data discipline. But schemas in the Schema Registry, provide the explicit contract that a program generating events provides to other programs that are consuming those events. Implementing schemas over your data is essential for any long-lived event streaming system, particularly ones that share data between different microservices or teams. Programs that will vary independently of one another, and that will value having a well-defined contract for the data that they share. We'll kick off the first module of the Schema Registry course by diving into the key concepts for using schemas as contracts, and how they're stored in a Schema Registry. We'll start off generally, first discussing Kafka's loosely coupled design and how it solves one problem, but opens the door for another, allowing client applications to potentially get out of sync with each other, as you make changes to the design and structure of your model objects. Then, we'll describe how a Schema Registry provides what you need to keep client applications in sync with the data changes in your organization or business. So let's dive in, and start learning about the Schema Registry. Applications that leverage Kafka fall into two categories. They're either producers or consumers. Or both, in some cases, but let's keep it simple for now. Producers are applications that generate messages or events that are then published to Kafka. These messages take the form of key value records that the producers serialize into byte arrays and then send over to the Kafka brokers. The brokers store these serialized records into designated topics. On the other hand, consumers are applications that subscribe to one or more topics. They request the stored events from Kafka, and then process them. Consumers must be able to deserialize the bytes, returning them to their original record format. This creates an implicit contract between the produce and consumer applications. There's an assumption from the producer that the consumer will understand the format of the message. Meanwhile, the consumer also assumes that the producer will continue to send the messages in the same format. Now, that seems like a totally reasonable set of assumptions. But what if they weren't? As you may have experienced, applications are rarely static. Over time, they evolve as new business requirements develop and these new requirements can result in changes to the format of the message. Now, this could be something simple, like adding or removing a field, or maybe it could be a little more complex, involving structural changes to the message. It may even mean a different serialization format, like converting between Avro and Protobuf. If both the producer and consumer aren't updated at the same time, then we've broken the contract. We could end up in a situation where the producer is using one format, while the consumer is expecting something entirely different. And the result, is that messages could get stuck in the topic, and the consumer may be unable to proceed. In the real world, when we want to establish a concrete set of rules for how two parties should behave, we sometimes do that in the form of a legal contract. If either of the two parties violates that contract, there are consequences. We want to provide a similar contract in software. If either our producer or consumer fails to meet the rules established by the contract, then there should be a consequence. This contract is codified in something called a schema. So what's a schema? A schema is a set of rules that establishes the format of the messages being sent and received. More technically, it outlines the structure of the message, the names of any fields, what data types they contain, and any other important details. This schema is a contract between the two applications, and both the producer and the consumer are expected to support the schema. If the schema needs to change for any reason at all, then we need to have processes in place to handle that change. For example, we may need to support the old schema for a period of time while both applications are being updated. Returning to the legalese of the real world, when a contract is written, someone is assigned to arbitrate that contract and ensure that it's followed. This is generally handled by lawyers. In software, the arbiter of the contract is something known as a Schema Registry. The Schema Registry is a service that records the various schemas and their different versions as they evolve over time. Producer and consumer clients retrieve schemas from the Schema Registry via HTTPS, store them locally in cache, and then use them to serialize and deserialize messages sent to and received from Kafka. This schema retrieval occurs only once for a given schema, and from that point on, the cached copy is relied upon. Confluent provides a Schema Registry that can be integrated directly into Kafka applications. And it's versatile, supporting Avro, Protobuf and JSON schema formats. Now, while much of the information in this course is applicable to any Schema Registry, its focus is on the Confluent's Schema Registry. As such, from this point onward, we'll refer to it simply as the Schema Registry, with the understanding that it's the Confluent Schema Registry being discussed. As you go through this course, you'll learn how the Schema Registry can enforce the previously mentioned contract between your applications. At a high level, the course covers the schema workflow when using Schema Registry, how to utilize each of the schema formats supported by Schema Registry, managing schemas, integrating with client applications, schema subjects and schema compatibility. Throughout this course, we'll be introducing you to Schema Registry through hands-on exercises that will have you produce data to, and consume data from, Confluent Cloud. If you haven't already created a Confluent Cloud account, take some time now to sign up so that you're ready to go with the first exercise. Be sure to use the promo code when signing up, to get the $101 of free usage that it provides. First off, you'll want to follow the URL on the screen. On the signup page, enter your name, email and password. Be sure to remember the sign-in details, as you'll need them to access your account later. Click the Start free button and wait to receive a confirmation email in your inbox. The link in the confirmation email will lead you to the next step, where you'll be prompted to set up your cluster. You can choose between a basic, standard or dedicated cluster. Basic and standard clusters are serverless offerings, where your free Confluent Cloud usage is only exhausted based on what you use, perfect for what we need today. For the exercises in this course, we'll choose the basic cluster. Usage costs will vary with any of these choices, but they are clearly shown at the bottom of the screen. That being said, once we wrap up these exercises, don't forget to stop and delete any resources that you created, to avoid exhausting your free usage. Click Review to get one last look at the choices you've made and give your cluster a name, then launch. It may take a few minutes for your cluster to be provisioned. And that's it! You'll receive an email once your cluster is fully provisioned. But in the meantime, let's go ahead and leverage that promo code. From settings, choose Billing & payment. You'll see here that you have $400 of free Confluent Cloud usage, but if you select the Payment details & context tab, you can either add a credit card or choose to enter a promo code. And with that done, you're ready to dive in.