Inside the Apache Kafka Broker



Jun Rao
Co-Founder, Confluent (Presenter)
Kafka Manages Data and Metadata Separately
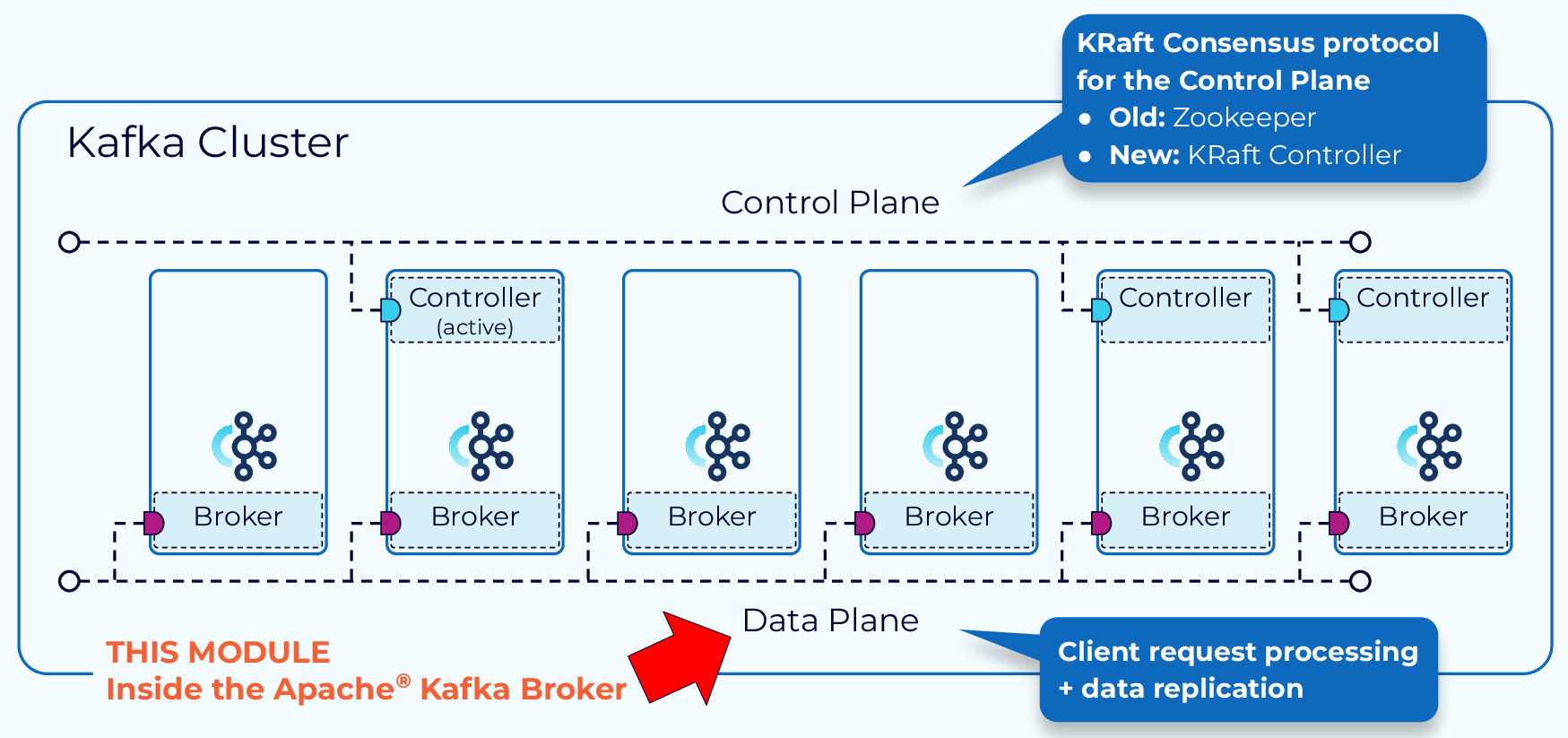
The functions within a Kafka cluster are broken up into a data plane and a control plane. The control plane handles management of all the metadata in the cluster. The data plane deals with the actual data that we are writing to and reading from Kafka. In this module we will focus on how the data plane handles client requests to interact with the data in our Kafka cluster.
Inside the Apache Kafka Broker
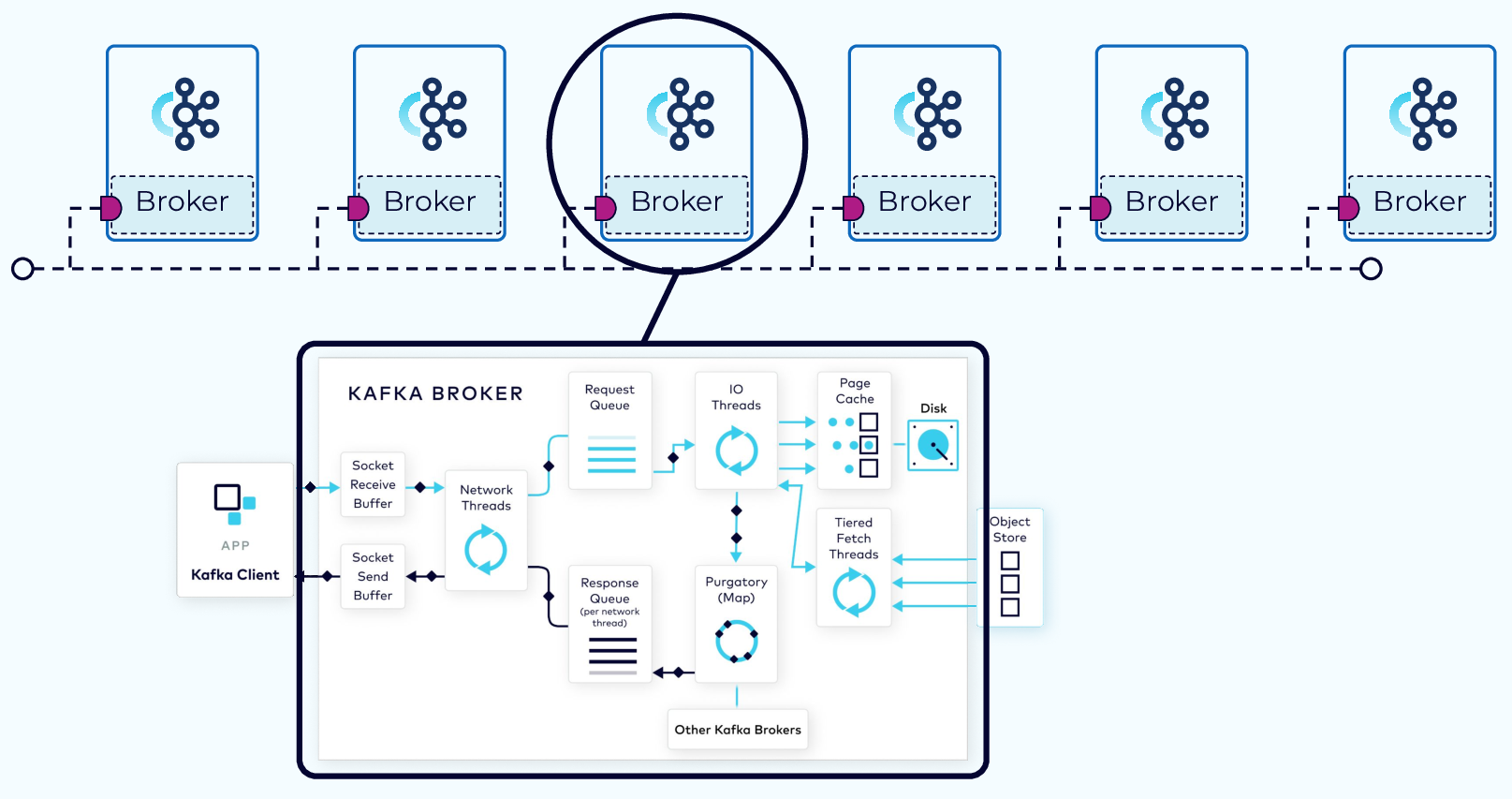
Client requests fall into two categories: produce requests and fetch requests. A produce request is requesting that a batch of data be written to a specified topic. A fetch request is requesting data from Kafka topics. Both types of requests go through many of the same steps. We’ll start by looking at the flow of the produce request, and then see how the fetch request differs.
The Produce Request
Partition Assignment
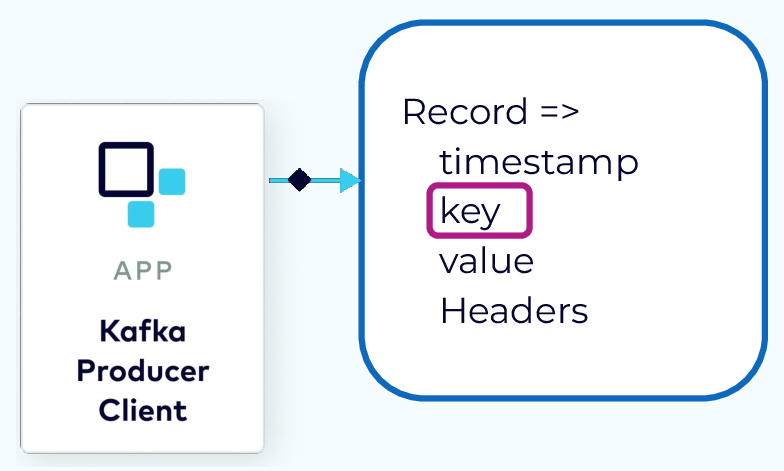
When a producer is ready to send an event record, it will use a configurable partitioner to determine the topic partition to assign to the record. If the record has a key, then the default partitioner will use a hash of the key to determine the correct partition. After that, any records with the same key will always be assigned to the same partition. If the record has no key then a partition strategy is used to balance the data in the partitions.
Record Batching
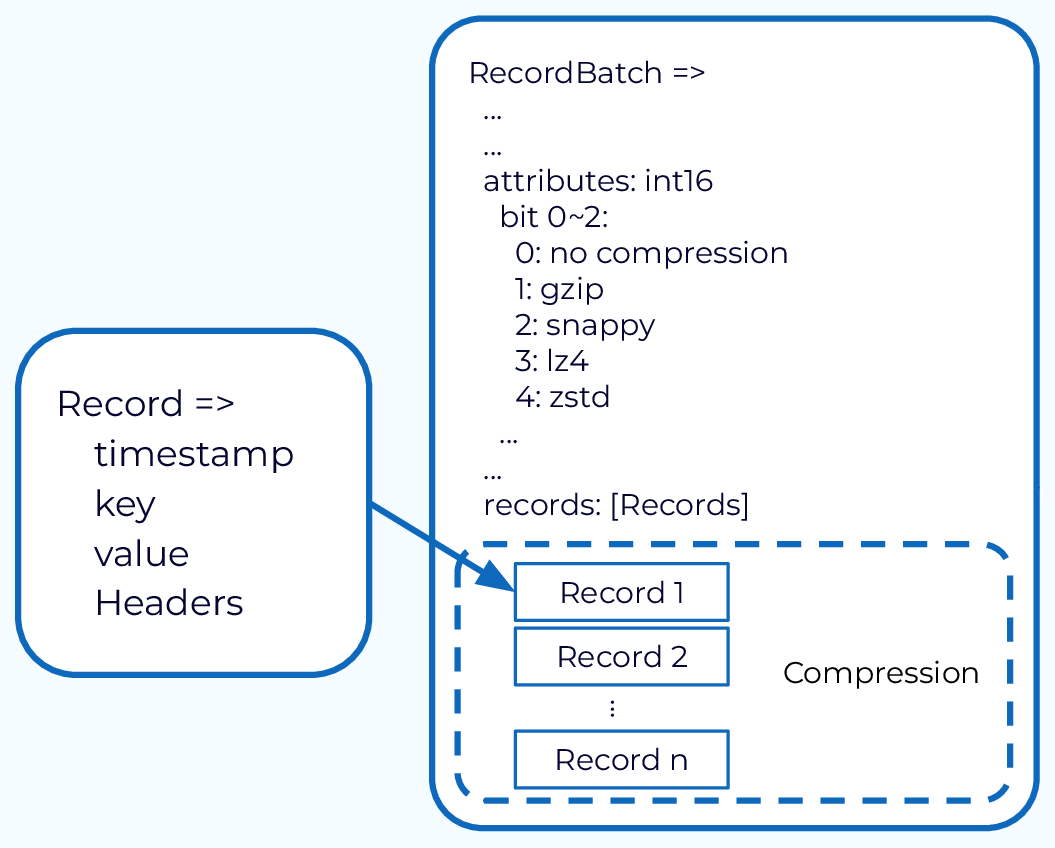
Sending records one at a time would be inefficient due to the overhead of repeated network requests. So, the producer will accumulate the records assigned to a given partition into batches. Batching also provides for much more effective compression, when compression is used.
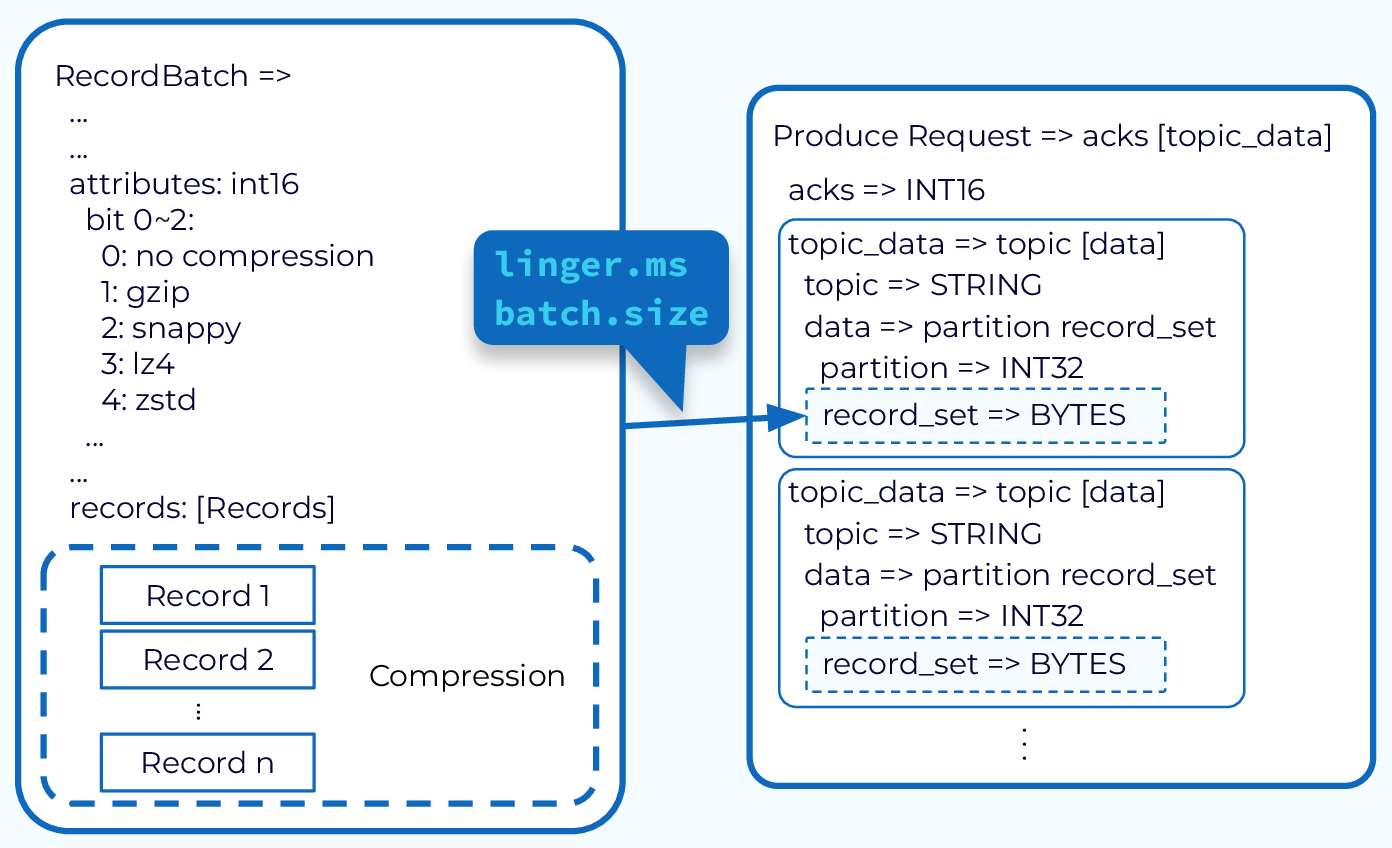
The producer also has control as to when the record batch should be drained and sent to the broker. This is controlled by two properties. One is by time. The other is by size. So once enough time or enough data has been accumulated in those record batches, those record batches will be drained, and will form a produce request. And this produce request will then be sent to the broker that is the leader of the included partitions.
Network Thread Adds Request to Queue
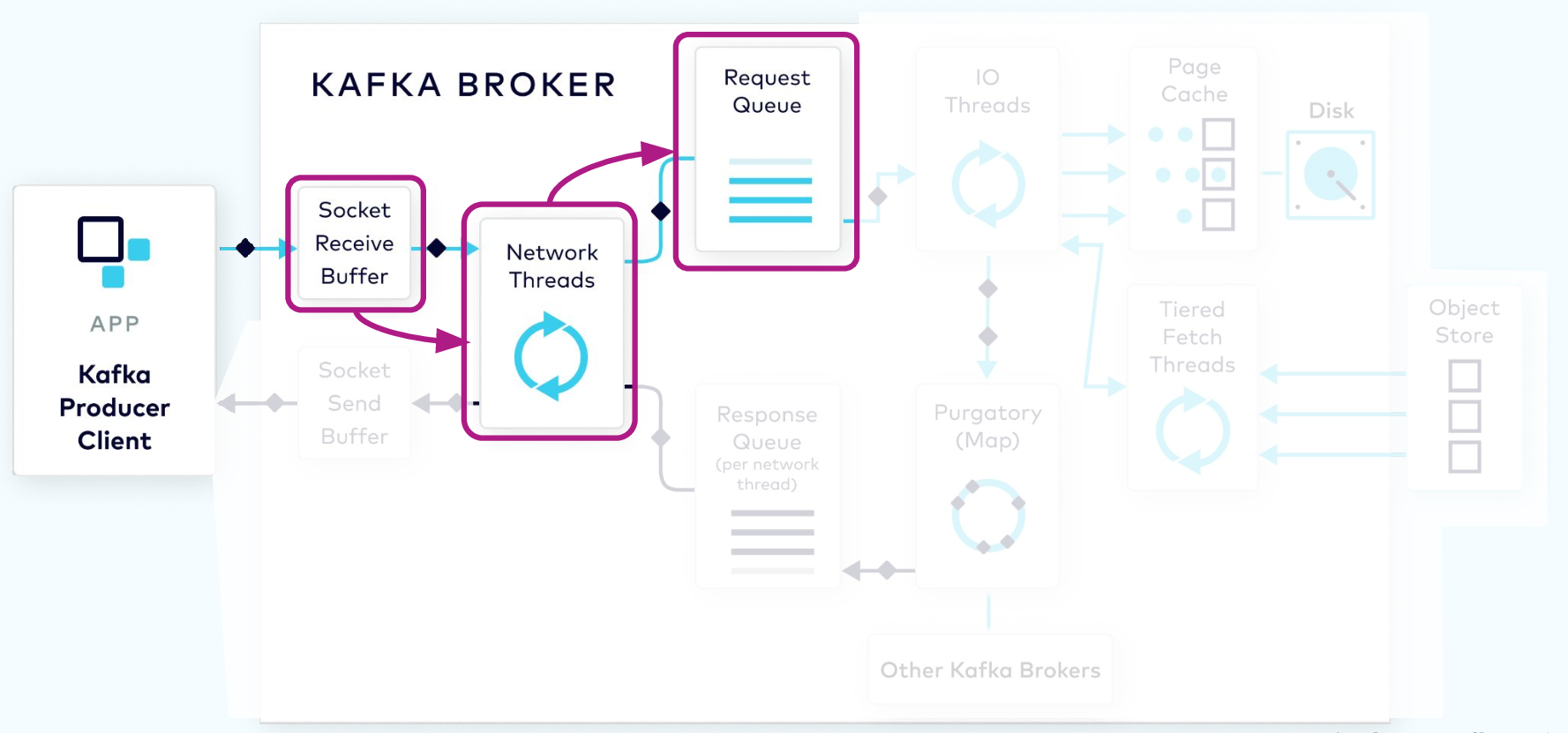
The request first lands in the broker’s socket receive buffer where it will be picked up by a network thread from the pool. That network thread will handle that particular client request through the rest of its lifecycle. The network thread will read the data from the socket buffer, form it into a produce request object, and add it to the request queue.
I/O Thread Verifies and Stores the Batch
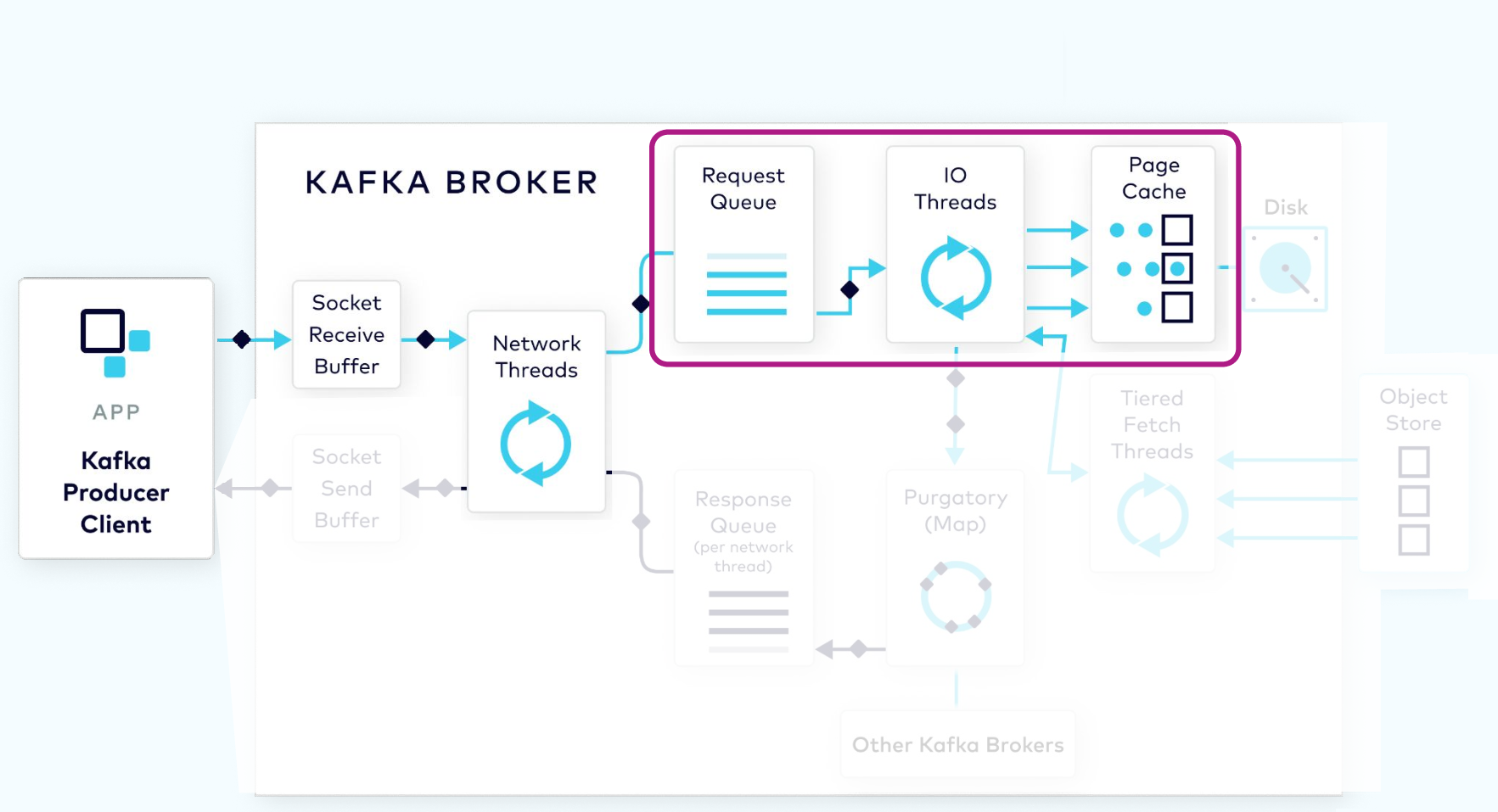
Next, a thread from the I/O thread pool will pick up the request from the queue. The I/O thread will perform some validations, including a CRC check of the data in the request. It will then append the data to the physical data structure of the partition, which is called a commit log.
Kafka Physical Storage
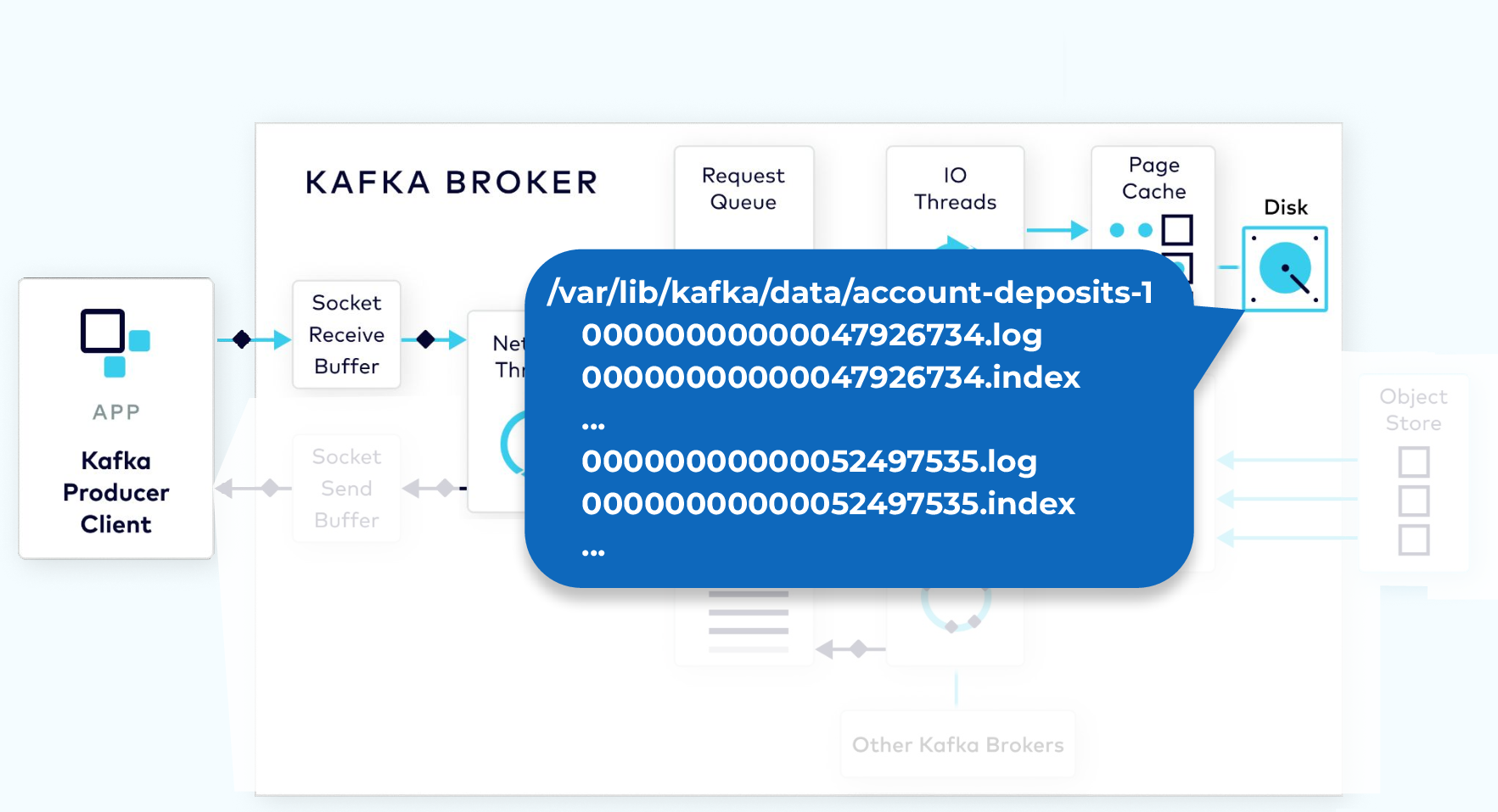
On disk, the commit log is organized as a collection of segments. Each segment is made up of several files. One of these, a .log file, contains the event data. A second, a .index file, contains an index structure, which maps from a record offset to the position of that record in the .log file.
Purgatory Holds Requests Until Replicated
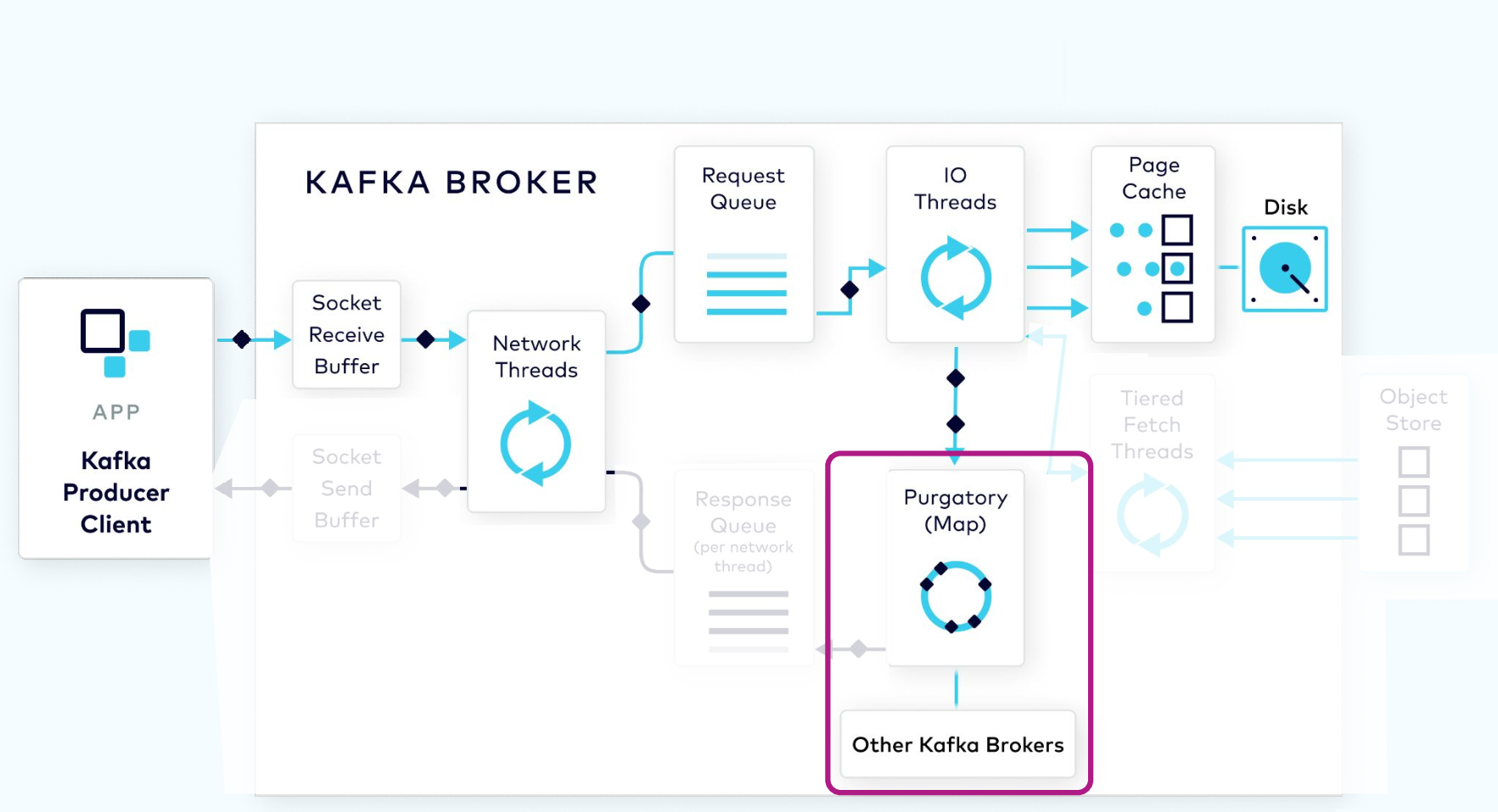
Since the log data is not flushed from the page cache to disk synchronously, Kafka relies on replication to multiple broker nodes, in order to provide durability. By default, the broker will not acknowledge the produce request until it has been replicated to other brokers.
To avoid tying up the I/O threads while waiting for the replication step to complete, the request object will be stored in a map-like data structure called purgatory (it’s where things go to wait).
Once the request has been fully replicated, the broker will take the request object out of purgatory, generate a response object, and place it on the response queue.
Response Added to Socket
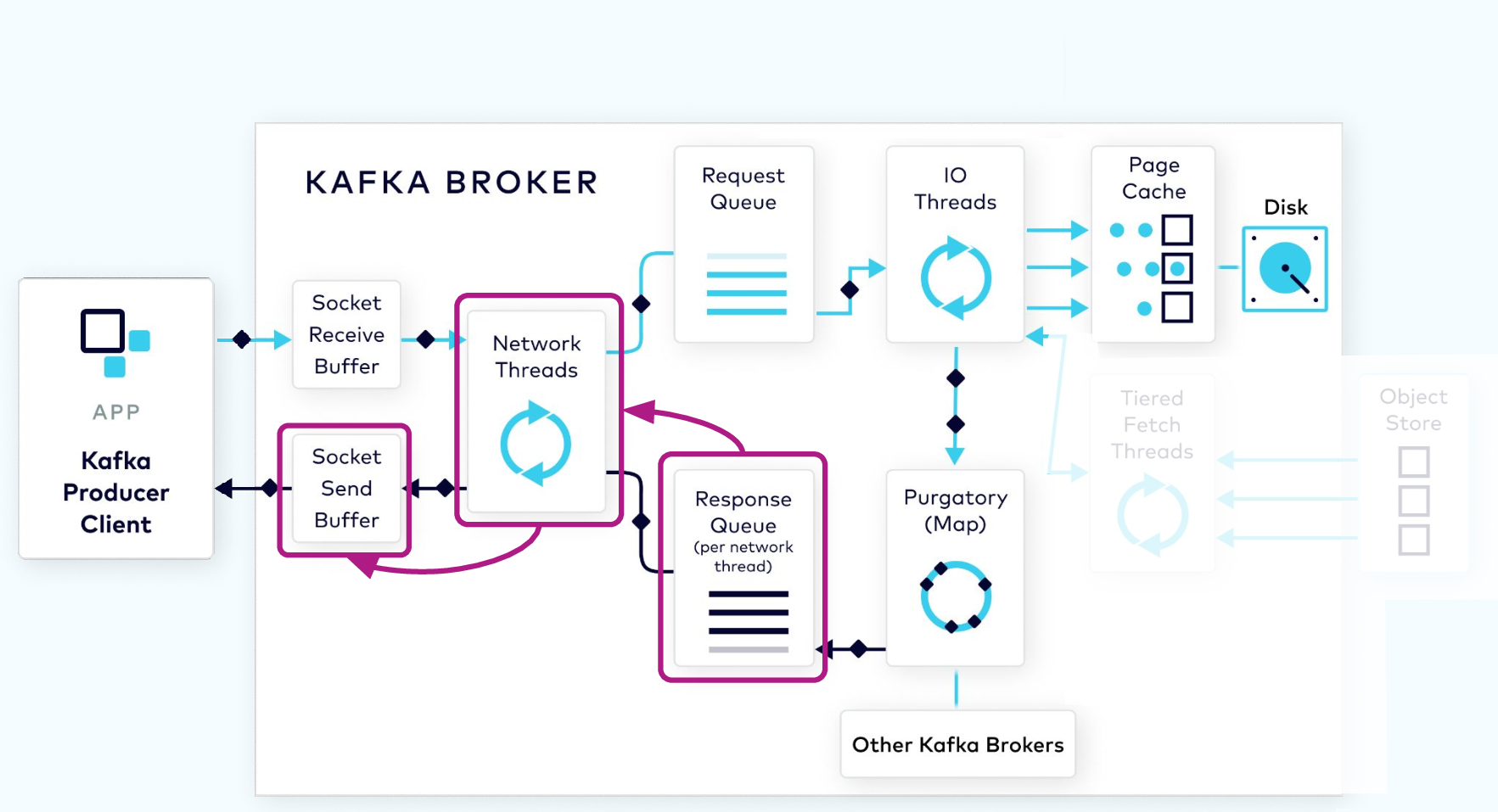
From the response queue, the network thread will pick up the generated response, and send its data to the socket send buffer. The network thread also enforces ordering of requests from an individual client by waiting for all of the bytes for a response from that client to be sent before taking another object from the response queue.
The Fetch Request
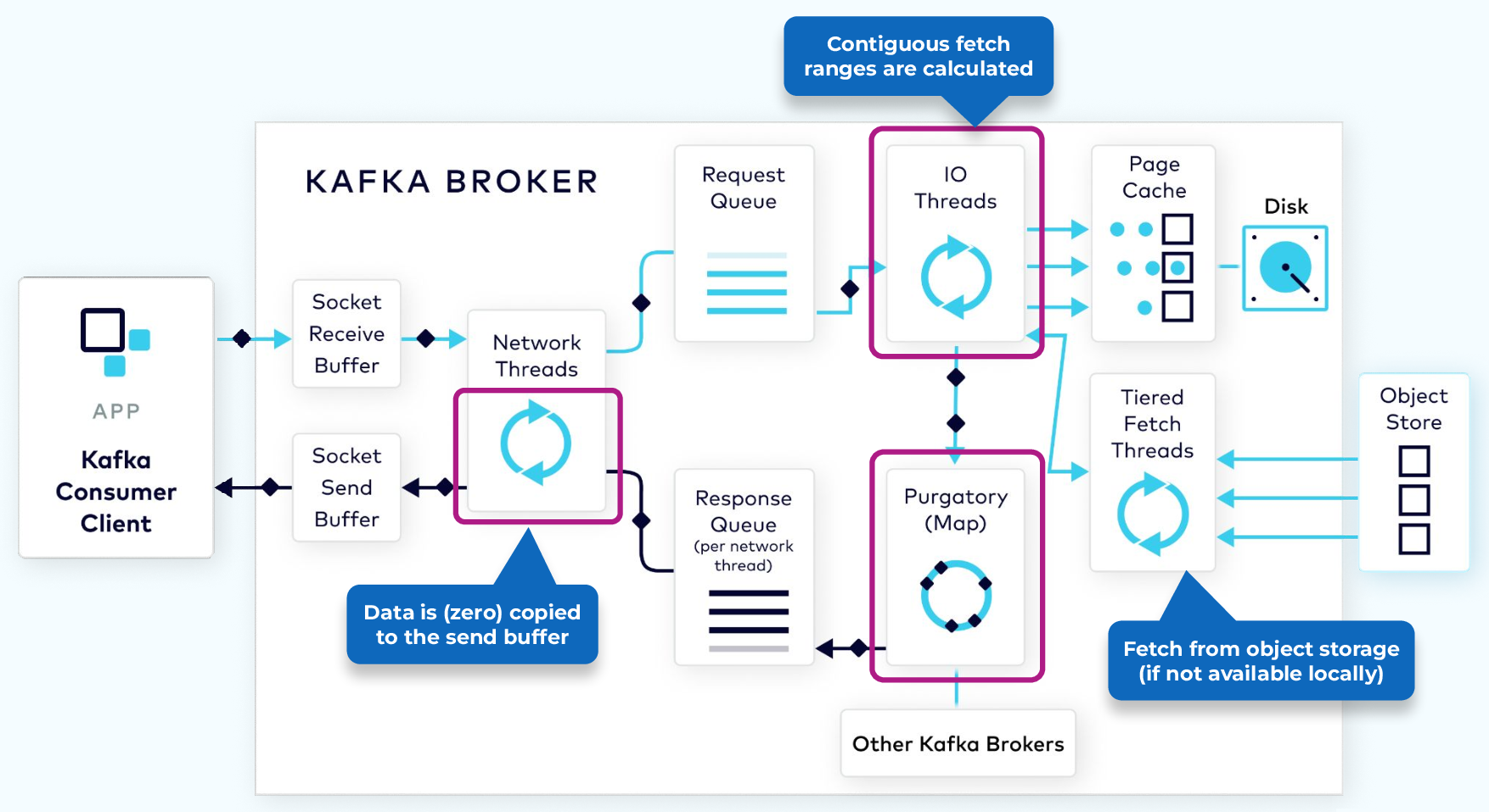
In order to consume records, a consumer client sends a fetch request to the broker, specifying the topic, partition, and offset it wants to consume. The fetch request goes to the broker’s socket receive buffer where it is picked up by a network thread. The network thread puts the request in the request queue, as was done with the produce request.
The I/O thread will take the offset that is included in the fetch request and compare it with the .index file that is part of the partition segment. That will tell it exactly the range of bytes that need to be read from the corresponding .log file to add to the response object.
However, it would be inefficient to send a response with every record fetched, or even worse, when there are no records available. To be more efficient, consumers can be configured to wait for a minimum number of bytes of data, or to wait for a maximum amount of time before returning a response to a fetch request. While waiting for these criteria to be met, the fetch request is sent to purgatory.
Once the size or time requirements have been met, the broker will take the fetch request out of purgatory and generate a response to be sent back to the client. The rest of the process is the same as the produce request.
Use the promo code INTERNALS101 to get $25 of free Confluent Cloud usage
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.
Inside the Apache Kafka Broker
Hi, everyone, Jun Rao from Confluent. In this module, we're going to take a walk inside a Kafka broker. Within a Kafka cluster, we have a separate control plane and a data plane. The control plane is responsible for handling all of the metadata of the cluster, and the data plane, of course, is used to handle all of the actual data. And in this particular module, I'm going to talk about how the data plane is used to handle all of the client requests. Types of Requests There are two main types of requests each broker is handling, one is the produce request from the producer, and the other is fetch requests from the consumer. Both types of requests are going through a few common steps on the broker, and we'll go through them one by one. First, let's go through how a produce request is handled. Sending a Record The producer client starts by sending a record. Then the producer library will use a pluggable partitioner to decide which partition in this topic this record should be assigned to. If a key is specified in the record, the default partition assigner will use the key to hash into a particular topic partition deterministically, and always route the records with the same key to that same partition. If the key is not specified, then this record will be selected in a round-robin way for the next partition. Sending each record as itself is not going to be efficient, because it has too much overhead. Instead, what a producer library does is to buffer all those records for a particular partition in an in-memory data structure, which we call record batches. Accumulating the data in record batches also allows compression to be done in a more efficient way, because compression of a bunch of records together is much more efficient than compressing them individually. The producer also has control as to when the record batch should be drained and sent to the broker. This is controlled by two properties. One is by time. The other is by size. So once enough time or enough data has been accumulated in those record batches, those record batches will be drained, and will form a produce request. And this produce request will then be sent to the corresponding broker. Produce Requests The produce request will first land in the socket receive buffer on the broker. From there, it'll be picked up by one of the network threads. Once a network thread picks up a particular client request, it will stick to that particular client for the rest of its life. Since each of the network threads is used to multiplex across multiple clients, the network thread is designed to only do work that's lightweight. For the most part, the network thread just takes those bytes from the socket buffer, and forms a produce request object, and puts that into a shared request queue. IO Threads From there, the request will be picked up by the second main pool in Kafka. These are called I/O threads. Unlike the network threads, each I/O thread can be used to handle requests from any client. So all of those I/O threads will be diving into this shared request queue, and they will be grabbing the next request that's available. The I/O thread will handle produce requests by first validating the CRC of the data associated with the partition, and then it'll be appending the data associated with the partition to a data structure, which we call a commit log. Committed Log The commit log is organized on disk in a bunch of segments. Each of the segments has two main parts. One is the actual data. This is where the actual data is appended into. And the second one is an index structure, which provides a mapping from the offset to the position of this record within this .log file. By default, the broker will only acknowledge the produce request once the data is fully replicated across other brokers, because we rely on replication to serve the purpose of durability, since we don't flush the data synchronously. While waiting for the data to be fully replicated, we don't want to tie up this I/O thread, because the number of I/O threads is limited. Instead what we'll do is to stash those pending produce requests into a data structure called purgatory. It's like a map. And then after that, this I/O thread can be freed up, and it can be used to process the next request. Once the data for the pending request is fully replicated, this pending produce request will be taken out of purgatory, and then a response will be generated, and will be put into the corresponding request response queue for the network thread. From there, the network thread will pick up the generated response, and will then send the response data into the send socket buffer. The network thread, as you can see here, is also responsible for enforcing ordering of the requests coming from a single client. So what it does is it will only take one request from a client at a time, and only after the completing of this request, when all the bytes for the response have been sent, this network thread will be able to take up the next request from that client. This is actually a pretty simple way to enforce ordering from a particular client. Fetch Handling Now, let's take a look at how the fetch request from the consumer client is handled. The consumer client, when it sends fetch requests, it will specify the topic and partition it wants to fetch data from, and, also, the starting offset where the data needs to be retrieved. The fetch requests will similarly go through the broker's receive buffer, which will be picked up by the network thread, and then fetch requests will be put into this shared request queue. What the I/O thread will do in this case is it will use the index structure that I mentioned earlier to find a corresponding file byte range using the offset index, so that it can know which range of bytes from the second file it needs to return to the consumer. Sometimes you may have a topic that has no new data. In this case, to keep returning empty results to the consumer is kind of wasteful and it's not efficient. So in this case, what a consumer can do is to specify a minimum number of bytes it needs to wait for the response, and a maximum amount of time it can afford to wait. So if there's not enough data, similar to the produce request, this fetch request will be first put into a purgatory structure, and will wait for enough bytes to be accumulated. So once enough bytes have been accumulated or enough time has passed, then this pending fetch request will be taken out of purgatory, and the corresponding fetch response will be generated and put into the response queue. From there, the network thread will pick it up to send the actual data in the response back to the client. In Kafka, we use zero copy transfer in the network thread to transfer the range of bytes from the underlying file directly to the remote socket. This is actually pretty efficient for memory management. Normally this process is pretty fast, because the data will still be in the page cache, and then copying data from memory to the socket buffer is pretty fast. But sometimes if you are accessing the old data, the data may need to be retrieved from disk. This can cause a network thread to be blocked. Since the network thread is shared by multiple clients, this may delay some of the processing for other clients on this network thread. In one of the future modules, we're going to talk about how the Tiered Storage capability is able to address this issue to provide better isolation when retrieving data from the consumer that's on disk. This is the end of this module. Thanks, everyone.