Cluster Elasticity



Jun Rao
Co-Founder, Confluent (Presenter)
Cluster Scaling
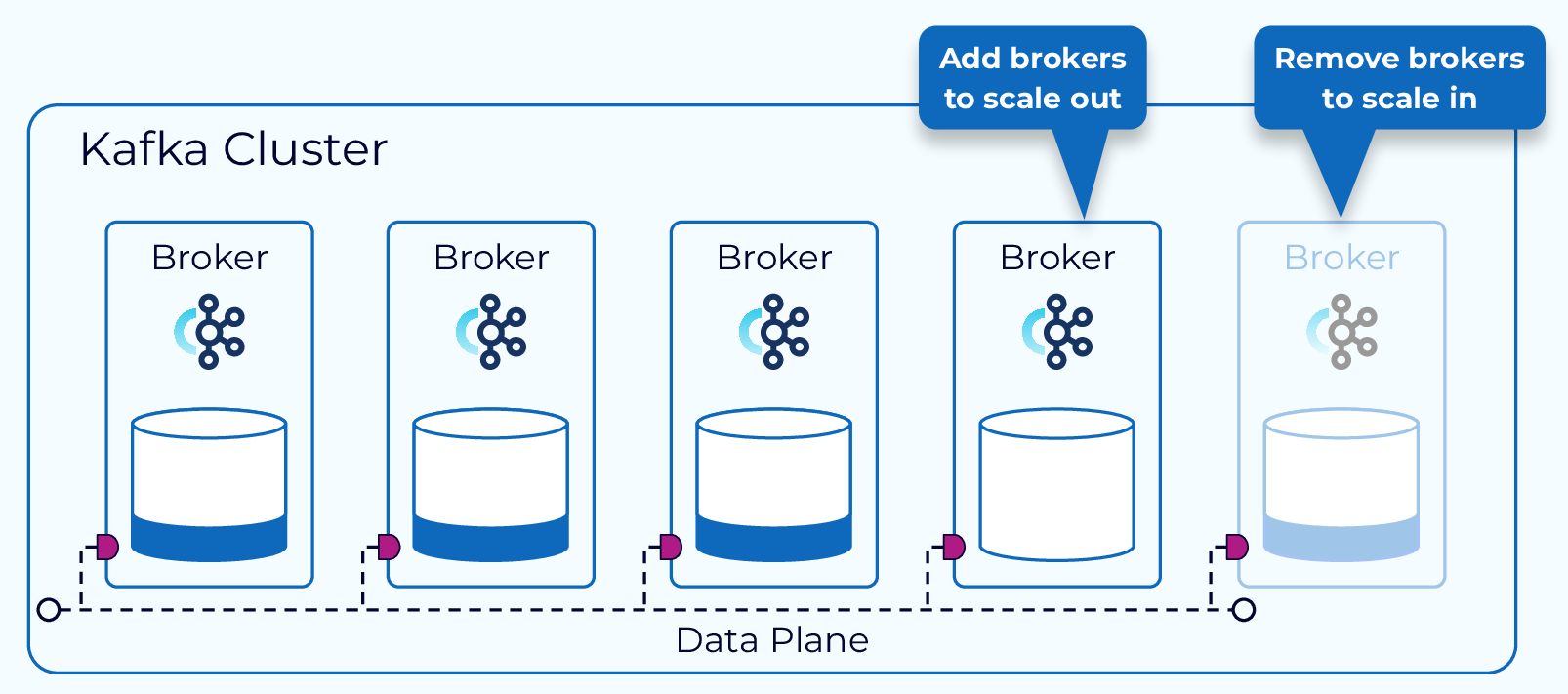
Kafka is designed to be scalable. As our needs change we can scale out by adding brokers to a cluster or scale in by removing brokers. In either case, data needs to be redistributed across the brokers to maintain balance.
Unbalanced Data Distribution
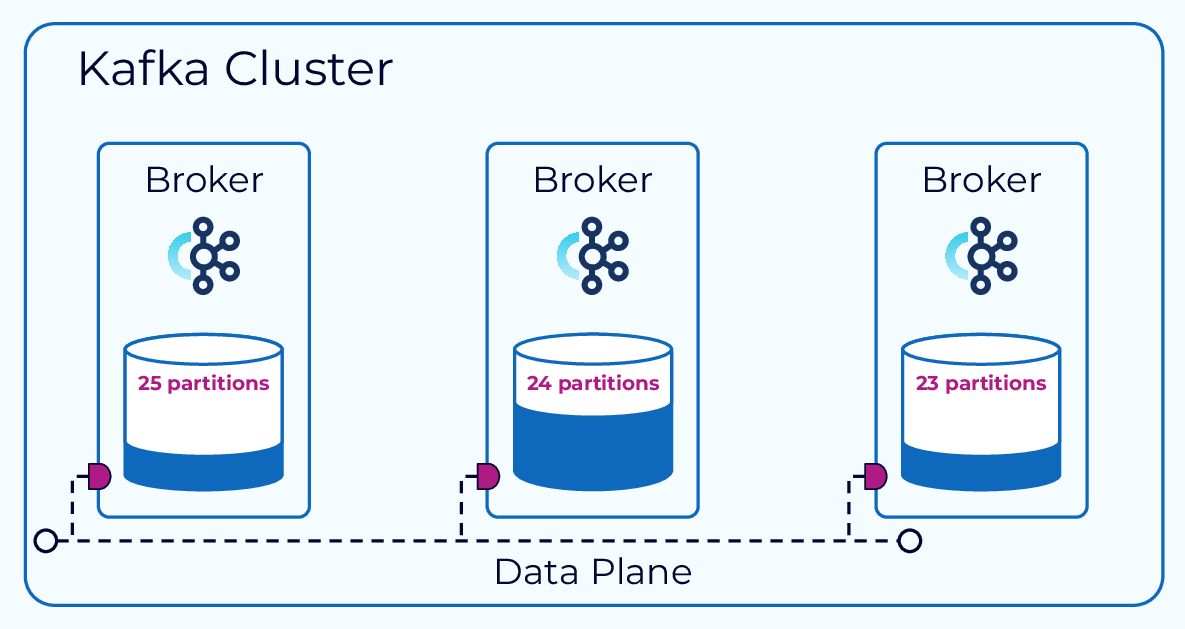
We can also end up needing to rebalance data across brokers due to certain topics or partitions being more heavily used than the average.
Automatic Cluster Scaling with Confluent Cloud

When using a fully managed service, such as Confluent Cloud, this issue goes away. With Confluent Cloud we don’t need to worry about balancing brokers. In fact, we don’t need to worry about brokers at all. We just request the capacity we need for the topics and partitions we are using and the rest is handled for us. Pretty sweet, huh?
Kafka Reassign Partitions
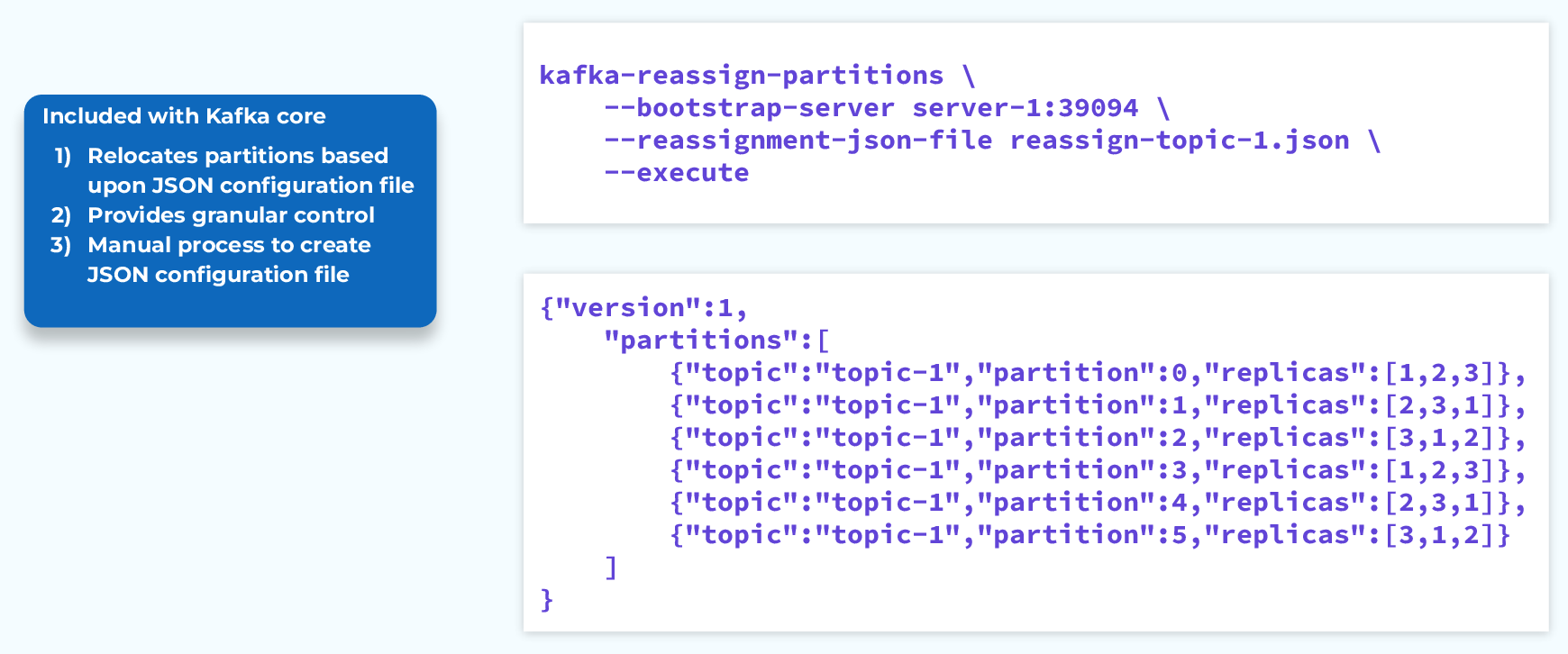
For self-managed Kafka clusters, we can use the command line utility, kafka-reassign-partitions.sh. First we create a JSON document that lays out how we want our topics and partitions distributed. Then we can pass that document to this command line tool, and if we include the --execute flag, it will go to work moving things around to arrive at our desired state. We can also leave the --execute flag off for a dry run.
This works well, but it is a very manual process and for a large cluster, building that JSON document could be quite the challenge.
Confluent Auto Data Balancer
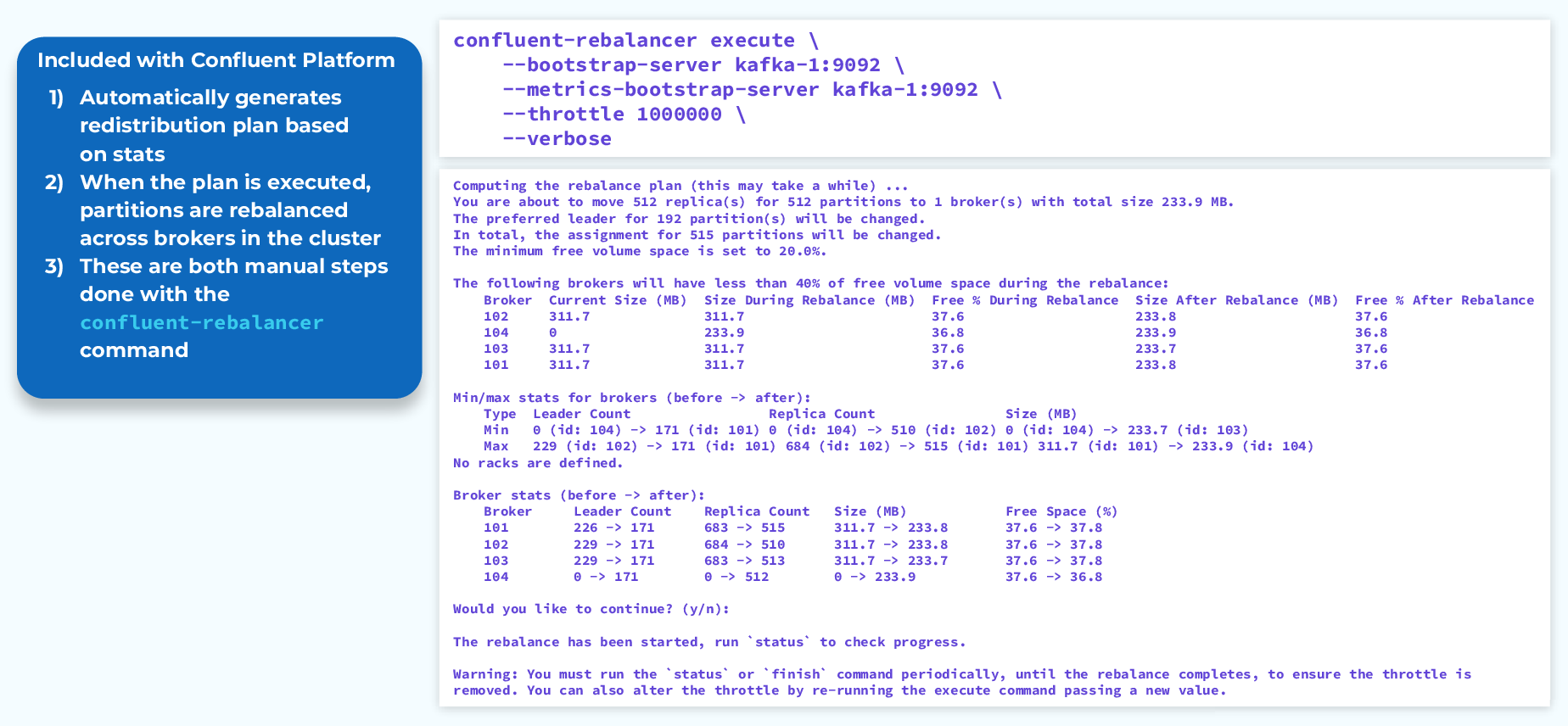
Confluent’s Auto Data Balancer takes this up a notch by generating the redistribution plan for us, based on cluster metrics. We use the confluent-rebalancer command to do these tasks, so it still takes some manual intervention, but it does a lot of the work for us.
Confluent Self-Balancing Clusters (SBC)
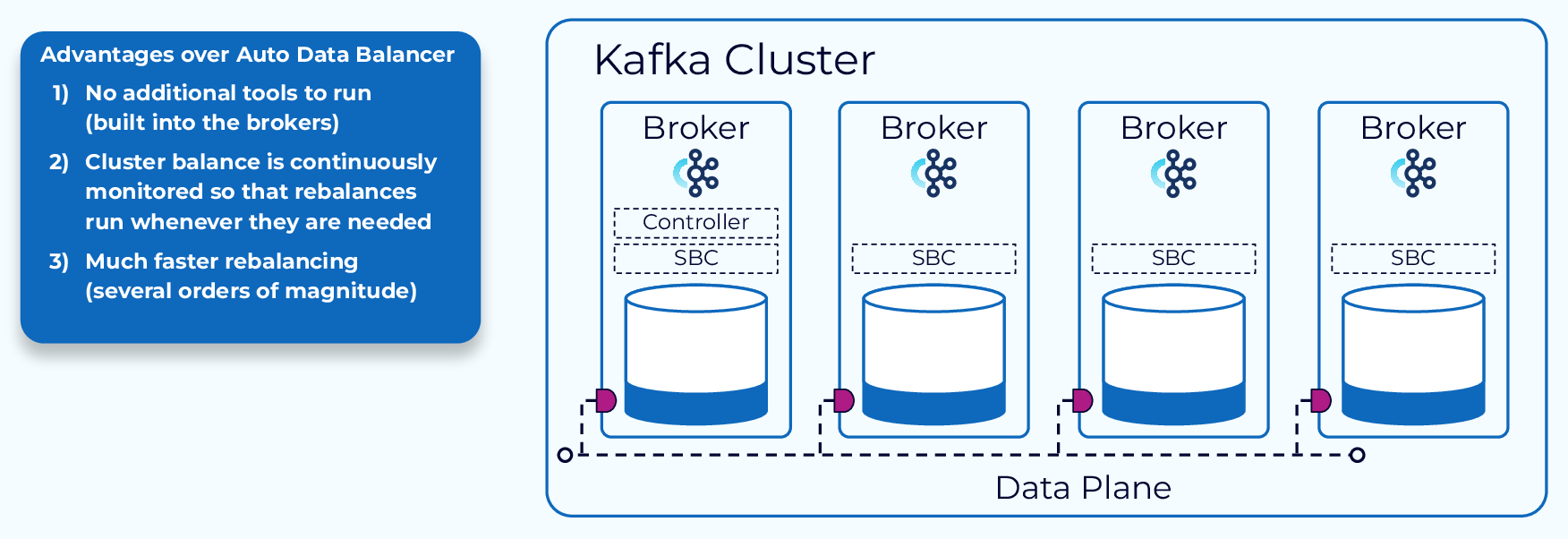
As cool as Auto Data Balancer is, it pales in comparison to Confluent Self-Balancing Clusters! As the name implies, self-balancing clusters maintain a balanced data distribution without us doing a thing. Here are some specific benefits:
- Cluster balance is monitored continuously and rebalances are run as needed.
- Broker failure conditions are detected and addressed automatically.
- No additional tools to run, it’s all built in.
- Works with Confluent Control Center and offers a convenient REST API.
- Much faster rebalancing.
SBC Metrics Collection and Processing
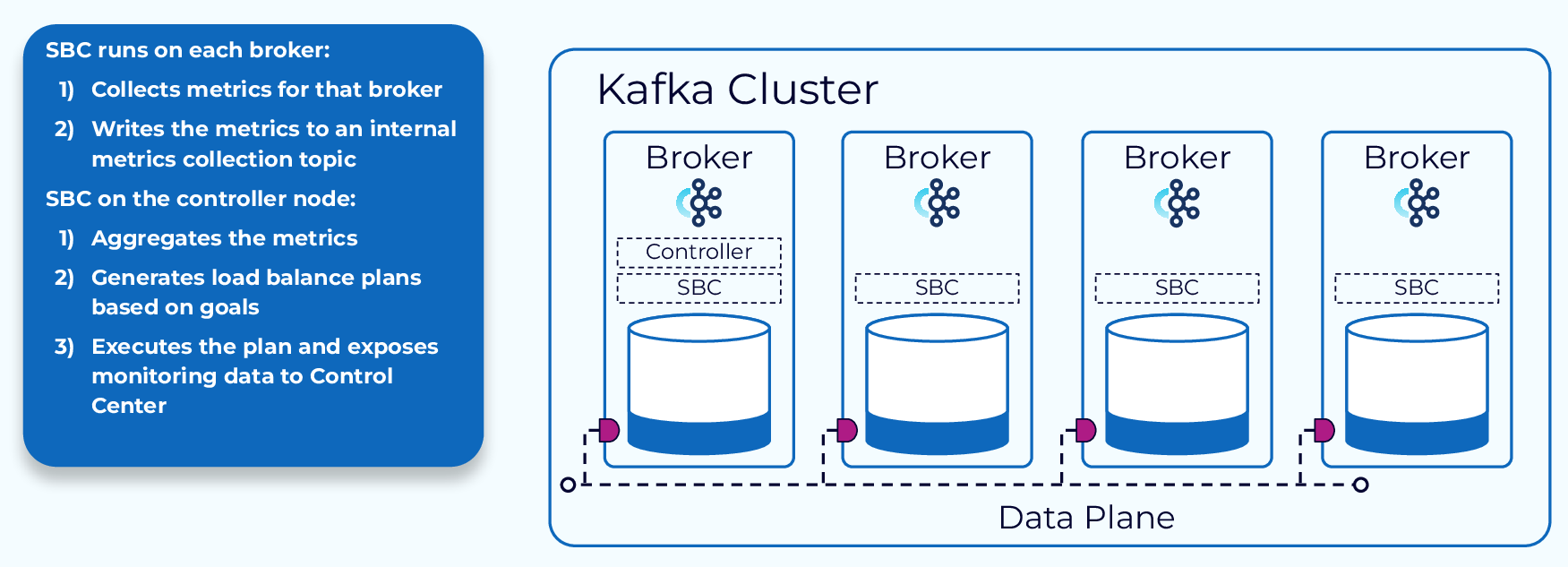
When SBC is enabled, each broker will run a small agent which will collect metrics and write them to an internal topic called _confluent-telemetry-metrics. The controller node will aggregate these metrics, use them to generate a redistribution plan, execute that plan in the background, and expose relevant monitoring data to Control Center.
SBC Rebalance Triggers
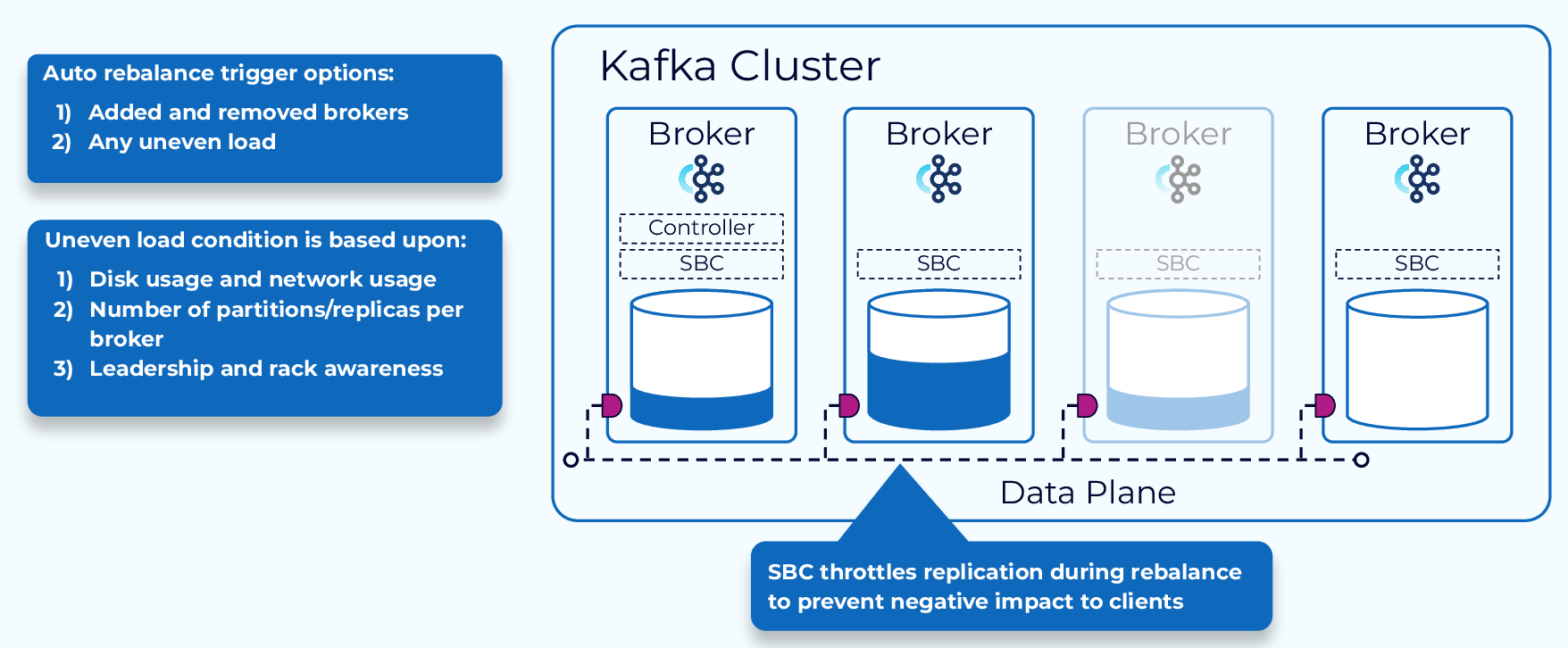
SBC has two options for triggering a rebalance. The first one is meant only for scaling and will trigger when adding or removing brokers. The other option is any uneven load. In this case, the rebalance will be based on the metrics that have been collected and will take into consideration things like disk and network usage, number of partitions and replicas per broker, and rack awareness. This is obviously the most foolproof method, but it will use more resources. SBC will throttle replication during a rebalance to minimize the impact to ongoing client workloads.
Fast Rebalancing with Tiered Storage
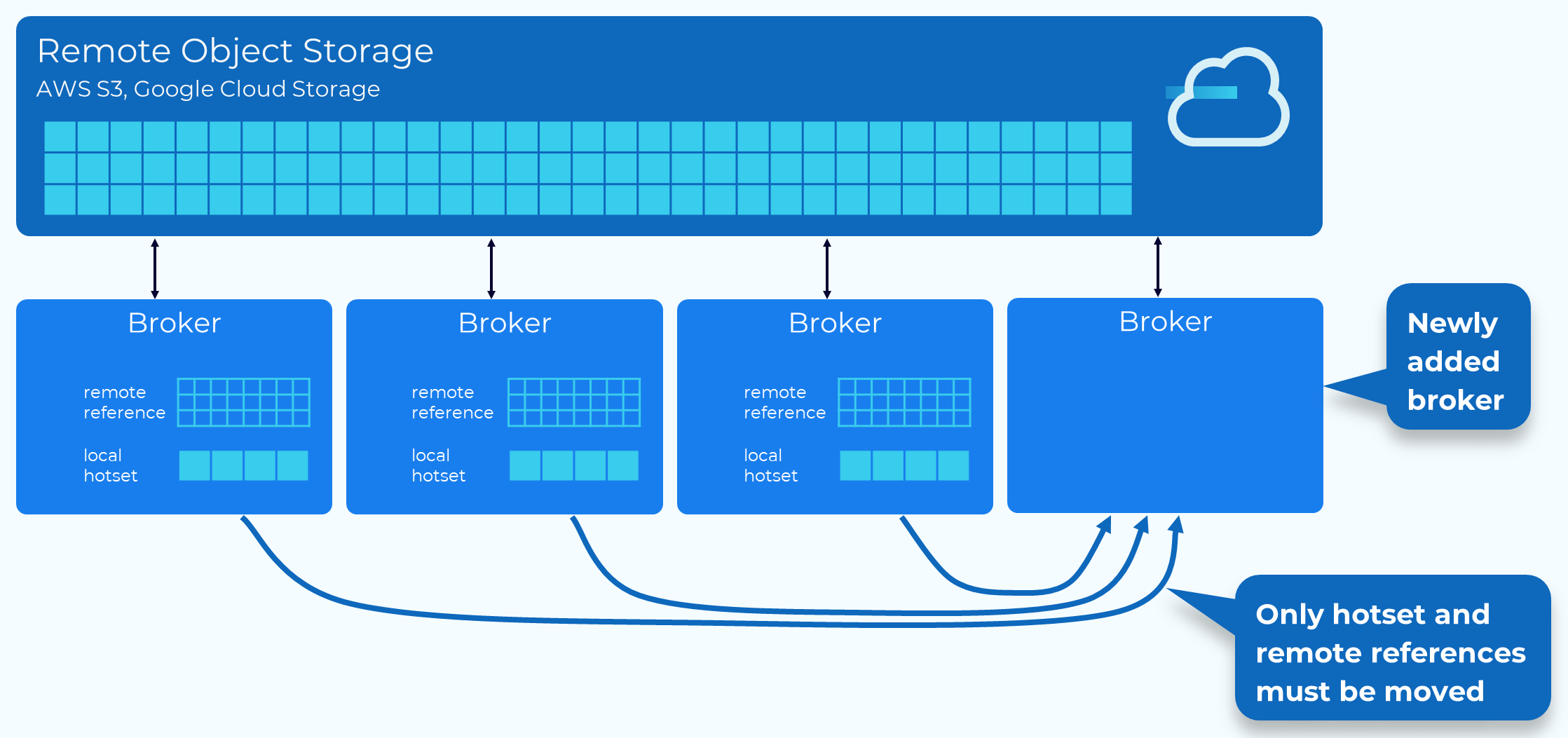
When combined with Tiered Storage, the rebalancing process is much faster and less resource intensive, since only the hotset data and remote store metadata need to be moved.
JBOD vs. RAID
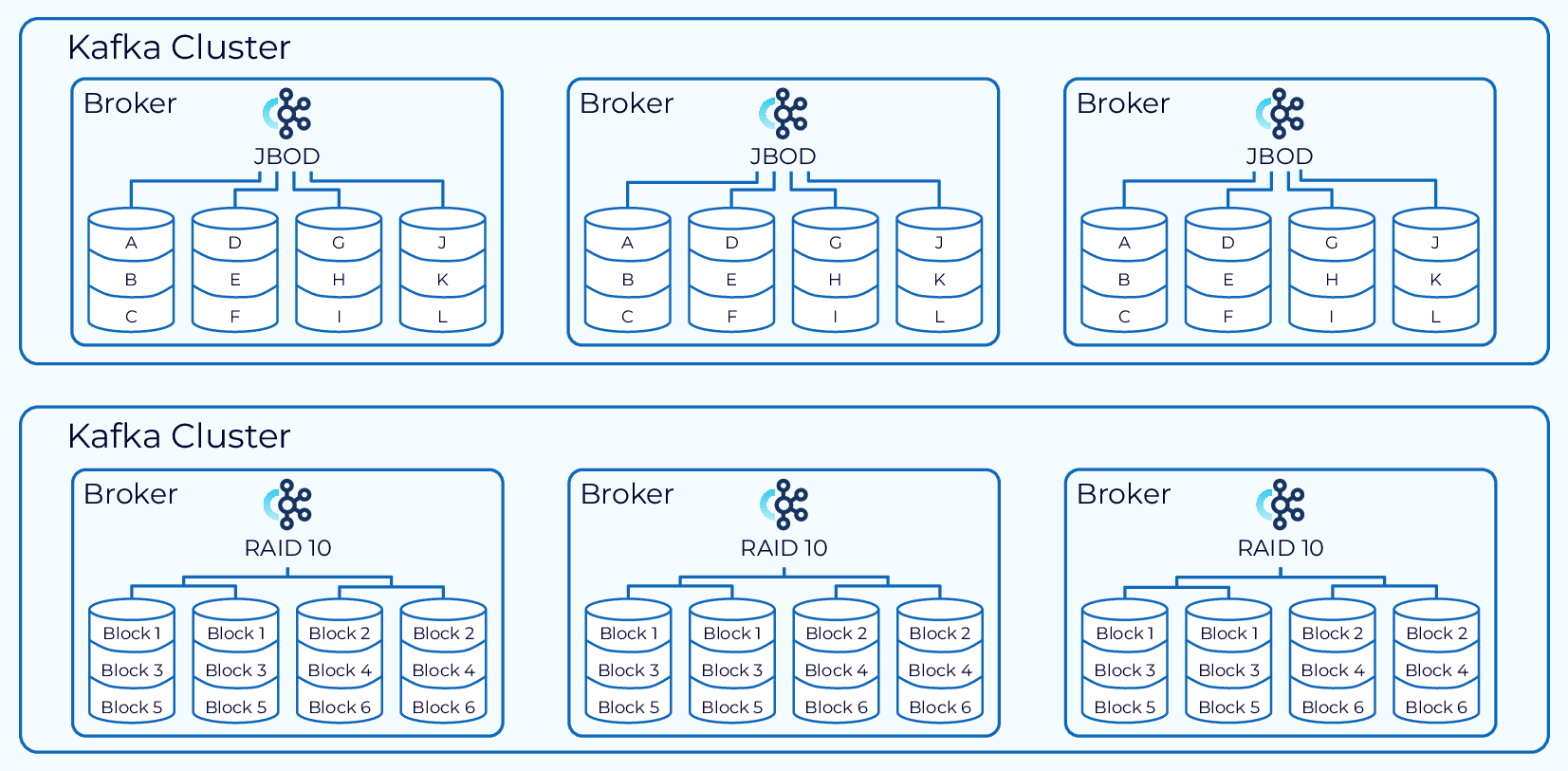
Sometimes, we may need multiple disks for a broker. In this situation we need to choose between a collection of individual disks (JBOD) or RAID. There are a lot of factors to consider here and they will be different in every situation, but all things being equal RAID 10 is the recommended approach.
Use the promo code INTERNALS101 to get $25 of free Confluent Cloud usage
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.
Cluster Elasticity
Hi everyone. Jun Rao from Confluent, here. In this module, we're going to talk about Kafka Elasticity. Kafka is designed as a distributed system so one of its strengths is it allows the system to be scaled out and scaled in as you need it. So if you are adding new brokers or removing brokers one of the things you have to do is to balance the load among the brokers because the new brokers may not have any data to start with. So in this case, you want to be able to shift some of the load from the existing brokers to the newly added brokers. Another reason why you need to move some of the data around is sometimes, over time, the load amount on brokers can be unbalanced because the exact amount of data across those topic partitions is not even. Now let's look at some of the ways how you can balance the data among those brokers. Kafka Reassignment Tool The good news is if you are using a managed service, like Confluent Cloud, this is actually done automatically for you, so you don't have to worry about balancing the data yourself. Next, let's look at some of the tooling you have if you're not using a managed service like Confluent Cloud. The first tool I'm going to talk about is actually available in Apache Kafka. It's called Kafka Reassignment Tool. So the way it works is if you want to move the data around, you first compose a JSON file to describe what is on the replica assignment you want to have for each of those topic partitions. And then once you've provided this, have this JSON file ready, you feed it into this command line tool and then execute it. And then once the command is executed, the broker will try to move the data from the current replica assignment to the new one over time. So while this tool gives you pretty good flexibility, you can control exactly the topic partitions you want to move around, it tends to be a little bit manual. So you have to manually prepare this JSON file and this is actually not convenient for the users who are not really confident administrators. Kafka Auto Data Balancer So another tool we have is actually from Confluent. This is called Auto Data Balancer. So it improves the partition reassignment tool by automatically generating that new execution plan for you. So when you run this through, you don't really need to specify that JSON file, you just point to a Kafka cluster and then the tool will look at some statistics across those brokers and then generate a plan automatically for you, and then you can run it. So this is actually an improvement from the previous tool, but it still needs to be manually triggered. So the latest tool we have from Confluent is called Self-Balancing Clusters. This tool improves auto data balancing by automating the process of data movement. In this case, you no longer need to run those manual tools, instead a self-balancing cluster monitors the clusters constantly and it will trigger the balancing automatically as it fits. And when it generates the plan to move the data around, it can also generate a plan in a much more efficient way to reduce the amount of data movement across brokers. Let's take a look at how SBC works in a bit more detail. What's happening is when SBC is enabled each of the brokers are running a little SBC agent. It's responsible for collecting some of the metrics on each broker such as how many leaders are in this broker and how many messages or bytes have been written to each of those topic leaders. And all those metrics will be collected in an internal topic, and then the controller node for SBC will collect and aggregate all those statistics and make a decision based on those metrics to see whether there's enough balance among those brokers and if so, it will generate a plan automatically for you. SBC makes the decision to trigger a rebalance on roughly two goals. The first one is if there's any changes in the broker, if some brokers are added or removed, that's an opportunity to trigger a rebalance. Another thing is if it senses any imbalance in the cluster. And that imbalance is determined based on information such as the leader, the amount of bytes, the amount of bytes written, and the amount of bytes read, as well. So when it generates a plan it will try to generate a plan that minimizes the move and also takes into consideration things like rack configuration, leader distribution, and other things. And while the plan is being executed, SBC will also automatically set up a throttling so that the movement doesn't overwhelm the ongoing client request. Tier Storage If you're running SBC with Tiered Storage enabled, the moving of the data will be even faster, as I mentioned earlier, because in this case, the majority of the data will be stored in a remote object store and when you try to add new brokers to move data to this new broker, the remote data doesn't need to be physically moved because it's only the references that need to be moved. So the rebalance, in this case, will be much faster. Local Storage The last thing I want to talk about in this module is some of the considerations for local storage. For some of the use cases, you may need to have multiple disks, volumes, associated with a particular broker. In this case, you have the choice to expose them either as individual disks, which is the JBOD model, or as a RAID. In the RAID case, we typically recommend RAID-10. So the JBOD model gives you the ability to use more storage, but it adds a burden since you have to think about balancing the load or the amount of data among those individual disks because you don't want them to be uneven. With Tiered Storage, this choice is made much easier because the majority of the data will be stored in a remote block store, so the local storage need is actually much smaller. In this case, the typical recommendation is you will just use all the disks in the RAID-10 mode and use that for storing the local storage. Outro And that's it for this module. Thanks for listening.